本文描述了 arrow 提供的各种数据对象类型,并记录了这些对象的结构。
arrow 包提供了几个对象类来表示数据。RecordBatch、Table 和 Dataset 对象是二维矩形数据结构,用于存储表格数据。对于列式一维数据,提供了 Array 和 ChunkedArray 类。最后,Scalar 对象表示单个值。下表总结了这些对象,并展示了如何使用 R6 类对象创建新实例,以及以更传统的 R 风格提供相同功能的便捷函数。
| 维度 | 类 | 如何创建实例 | 便捷函数 |
|---|---|---|---|
| 0 | Scalar |
Scalar$create(value, type) |
|
| 1 | 数组 |
Array$create(vector, type) |
as_arrow_array(x) |
| 1 | ChunkedArray |
ChunkedArray$create(..., type) |
chunked_array(..., type) |
| 2 | RecordBatch |
RecordBatch$create(...) |
record_batch(...) |
| 2 | 表 |
Table$create(...) |
arrow_table(...) |
| 2 | 数据集 |
Dataset$create(sources, schema) |
open_dataset(sources, schema) |
本文稍后将更详细地介绍这些内容。现在我们注意到,这些对象类中的每一个都对应于底层 Arrow C++ 库中同名的类。
除了这些数据对象,arrow 还定义了以下类来表示元数据
Schema是一个Field对象列表,用于描述表格数据对象的结构;其中Field指定一个字符串名称和DataType;并且DataType是一个控制值如何表示的属性
这些元数据对象在确保数据正确表示方面发挥着重要作用,所有三种表格数据对象类型(Record Batch、Table 和 Dataset)都包含用于表示元数据的显式 Schema 对象。要了解有关这些元数据类的更多信息,请参阅元数据文章。
标量
Scalar 对象只是一个可以是任何类型的单个值。它可能是一个整数、一个字符串、一个时间戳,或者 Arrow 支持的任何不同的 DataType 对象。arrow R 包的大多数用户不太可能直接创建 Scalar,但如果有需要,可以通过调用 Scalar$create() 方法来实现。
Scalar$create("hello")## Scalar
## hello数组
Array 对象是 Scalar 值的有序集合。与 Scalar 一样,大多数用户不需要直接创建 Array,但如果需要,有一个 Array$create() 方法允许您创建新的 Array。
integer_array <- Array$create(c(1L, NA, 2L, 4L, 8L))
integer_array## Array
## <int32>
## [
## 1,
## null,
## 2,
## 4,
## 8
## ]string_array <- Array$create(c("hello", "amazing", "and", "cruel", "world"))
string_array## Array
## <string>
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]Array 可以使用方括号进行子集,如下所示
string_array[4:5]## Array
## <string>
## [
## "cruel",
## "world"
## ]Array 是不可变对象:一旦 Array 创建,就不能修改或扩展。
分块数组
实际上,arrow R 包的大多数用户可能会使用分块数组而不是简单的数组。在底层,分块数组是一个或多个数组的集合,可以像单个数组一样进行索引。Arrow 提供此功能的原因在数据对象布局文章中描述,但就目前而言,只需注意分块数组在常规数据分析中表现得像数组即可。
为了说明这一点,我们使用 chunked_array() 函数
chunked_string_array <- chunked_array(
string_array,
c("I", "love", "you")
)chunked_array() 函数只是 ChunkedArray$create() 提供功能的包装器。我们来打印一下对象
chunked_string_array## ChunkedArray
## <string>
## [
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ],
## [
## "I",
## "love",
## "you"
## ]
## ]输出中的双括号旨在突出分块数组是围绕一个或多个数组的包装器这一事实。然而,尽管由多个不同的数组组成,分块数组可以像它们被端到端地放置在一个“类向量”对象中一样进行索引。这在下面进行了说明。
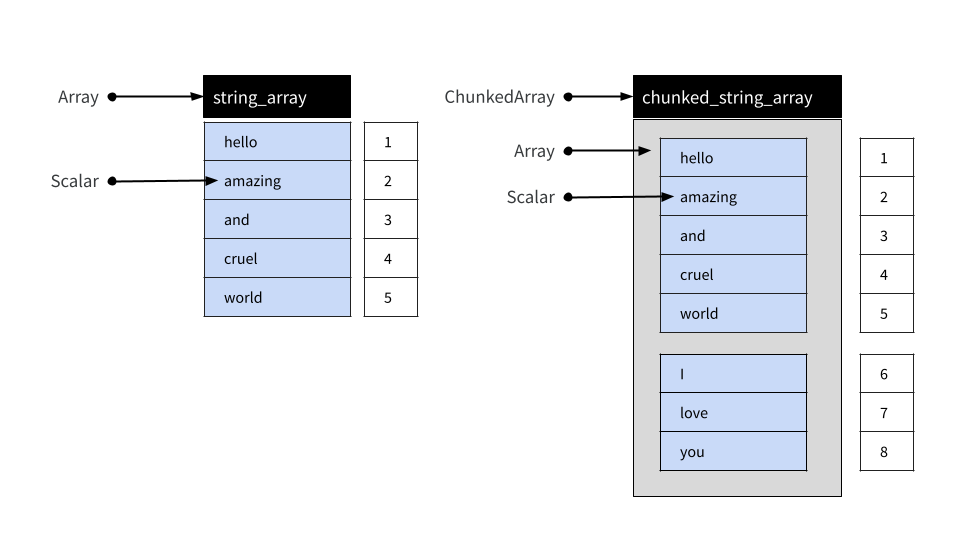
我们可以使用 chunked_string_array 来阐明这一点
chunked_string_array[4:7]## ChunkedArray
## <string>
## [
## [
## "cruel",
## "world"
## ],
## [
## "I",
## "love"
## ]
## ]需要注意的重要一点是,“分块”没有语义意义。它只是一个实现细节:用户绝不应将块视为有意义的单元。例如,将数据写入磁盘通常会导致数据被组织成不同的块。同样,两个包含相同值但分配给不同块的分块数组被认为是等效的。为了说明这一点,我们可以创建一个分块数组,它包含与 chunked_string_array[4:7] 相同的四个值,但组织成一个块而不是分成两个。
cruel_world <- chunked_array(c("cruel", "world", "I", "love"))
cruel_world## ChunkedArray
## <string>
## [
## [
## "cruel",
## "world",
## "I",
## "love"
## ]
## ]使用 == 进行相等性测试会产生逐元素比较,结果是一个包含四个(布尔类型)true 值的新分块数组
cruel_world == chunked_string_array[4:7]## ChunkedArray
## <bool>
## [
## [
## true,
## true,
## true,
## true
## ]
## ]简而言之,目的是让用户与分块数组交互时,就好像它们是普通的一维数据结构,而无需过多考虑底层分块安排。
分块数组在特定意义上是可变的:数组可以从分块数组中添加和删除。
记录批次
记录批次是包含命名数组的表格数据结构,以及伴随的 Schema,用于指定每个数组的名称和数据类型。记录批次是 Arrow 中数据交换的基本单元,但通常不用于数据分析。在分析上下文中,表和数据集通常更方便。
这些数组可以是不同类型,但长度必须相同。每个数组都被称为记录批次的“字段”或“列”之一。您可以使用 record_batch() 函数或 RecordBatch$create() 方法创建记录批次。这些函数非常灵活,可以接受多种格式的输入:您可以传递数据框、一个或多个命名向量、输入流,甚至包含适当二进制数据的原始向量。例如
rb <- record_batch(
strs = string_array,
ints = integer_array,
dbls = c(1.1, 3.2, 0.2, NA, 11)
)
rb## RecordBatch
## 5 rows x 3 columns
## $strs <string>
## $ints <int32>
## $dbls <double>这是一个包含 5 行 3 列的记录批次,其概念结构如下所示
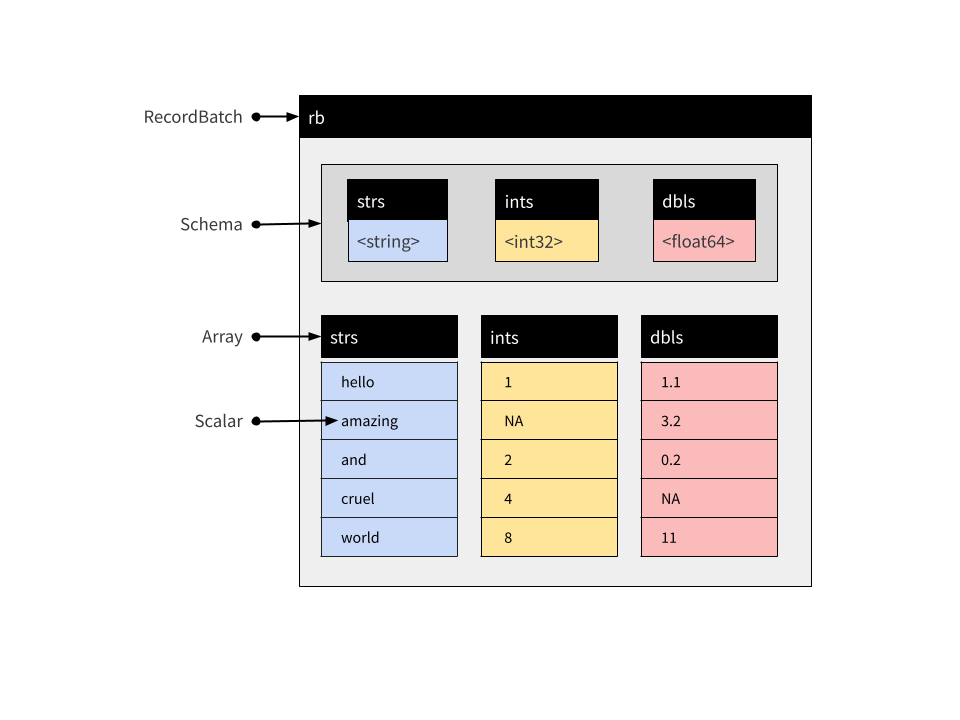
arrow 包为 Record Batch 对象提供了一个 $ 方法,用于按名称提取单个列。
rb$strs## Array
## <string>
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]您可以使用双括号 [[ 按位置引用列。rb$ints 数组是我们记录批次中的第二列,因此我们可以通过它来提取。
rb[[2]]## Array
## <int32>
## [
## 1,
## null,
## 2,
## 4,
## 8
## ]还有一个 [ 方法,允许您像数据框一样提取记录批次的子集。命令 rb[1:3, 1:2] 提取前三行和前两列。
rb[1:3, 1:2]## RecordBatch
## 3 rows x 2 columns
## $strs <string>
## $ints <int32>记录批次不能连接:因为它们由数组组成,而数组是不可变对象,所以一旦创建,就不能向记录批次添加新行。
表格
表由命名的 Chunked Array 组成,就像 Record Batch 由命名的 Array 组成一样。与 Record Batch 类似,表包含一个显式 Schema,指定每个 Chunked Array 的名称和数据类型。
您可以使用 $、[[ 和 [ 子集表,就像对 Record Batch 一样。与 Record Batch 不同,表可以连接(因为它们由 Chunked Array 组成)。假设第二个 Record Batch 到达
new_rb <- record_batch(
strs = c("I", "love", "you"),
ints = c(5L, 0L, 0L),
dbls = c(7.1, -0.1, 2)
)不可能创建一个 Record Batch 来将 new_rb 中的数据追加到 rb 中的数据,除非在内存中创建全新的对象。然而,使用 Table 我们可以
df <- arrow_table(rb)
new_df <- arrow_table(new_rb)我们现在将数据集的两个片段表示为 Table。Table 和 Record Batch 之间的区别在于所有列都表示为 Chunked Array。原始 Record Batch 中的每个 Array 都是 Table 中相应 Chunked Array 中的一个块。
rb$strs## Array
## <string>
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]df$strs## ChunkedArray
## <string>
## [
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]
## ]它是相同的基础数据——而且实际上,两个对象都引用了相同的不可变 Array——只是被一个新的、灵活的 Chunked Array 包装器包围。然而,正是这个包装器允许我们连接表。
concat_tables(df, new_df)## Table
## 8 rows x 3 columns
## $strs <string>
## $ints <int32>
## $dbls <double>生成的对象示意图如下所示
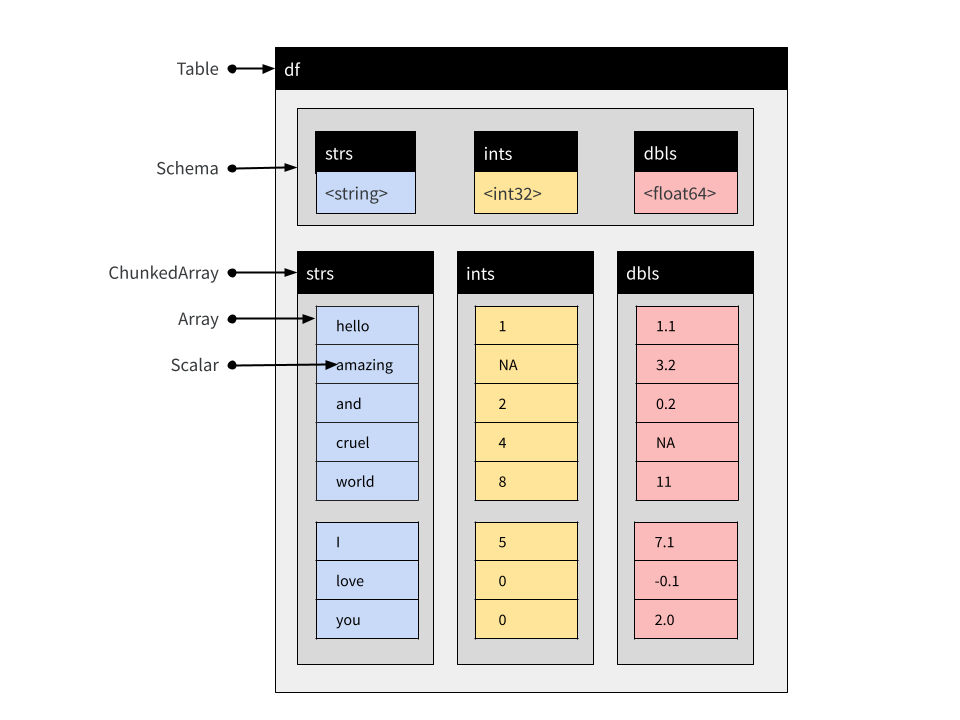
请注意,新 Table 中的 Chunked Array 保留了这种分块结构,因为原始 Array 都没有被移动。
df_both <- concat_tables(df, new_df)
df_both$strs## ChunkedArray
## <string>
## [
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ],
## [
## "I",
## "love",
## "you"
## ]
## ]数据集
与 Record Batch 和 Table 对象一样,Dataset 用于表示表格数据。在抽象层面,Dataset 可以被视为由行和列组成的对象,并且与 Record Batch 和 Table 一样,它包含一个显式 Schema,指定与每列关联的名称和数据类型。
然而,Table 和 Record Batch 是内存中明确表示的数据,而 Dataset 不是。相反,Dataset 是一种抽象,它引用存储在磁盘上的一个或多个文件中的数据。存储在数据文件中的值以批处理方式加载到内存中。加载仅在需要时进行,并且仅在对数据执行查询时进行。在这方面,Arrow Dataset 与 Arrow Table 是非常不同类型的对象,但用于分析它们的 dplyr 命令基本相同。在本节中,我们将讨论 Dataset 的结构。如果您想了解有关分析 Dataset 的实际细节,请参阅分析多文件数据集一文。
磁盘上的数据文件
简化到最简单的形式,数据集的磁盘结构只是一个数据文件集合,每个文件存储数据的子集。这些子集有时被称为“片段”,分区过程有时被称为“分片”。按照惯例,这些文件被组织成一个称为 Hive 样式分区的文件夹结构:有关详细信息,请参阅 hive_partition()。
为了说明这是如何工作的,让我们手动将一个多文件数据集写入磁盘,而不使用任何 Arrow Dataset 功能来完成这项工作。我们将从三个小数据框开始,每个数据框都包含我们想要存储的数据的一个子集。
df_a <- data.frame(id = 1:5, value = rnorm(5), subset = "a")
df_b <- data.frame(id = 6:10, value = rnorm(5), subset = "b")
df_c <- data.frame(id = 11:15, value = rnorm(5), subset = "c")我们的意图是每个数据框都应存储在单独的数据文件中。正如您所看到的,这是一个非常有结构的分区:所有 subset = "a" 的数据都属于一个文件,所有 subset = "b" 的数据都属于另一个文件,所有 subset = "c" 的数据都属于第三个文件。
第一步是定义并创建一个将保存所有文件的文件夹。
ds_dir <- "mini-dataset"
dir.create(ds_dir)下一步是手动创建 Hive 风格的文件夹结构
ds_dir_a <- file.path(ds_dir, "subset=a")
ds_dir_b <- file.path(ds_dir, "subset=b")
ds_dir_c <- file.path(ds_dir, "subset=c")
dir.create(ds_dir_a)
dir.create(ds_dir_b)
dir.create(ds_dir_c)请注意,我们以“键=值”格式命名了每个文件夹,精确描述了将写入该文件夹的数据子集。这种命名结构是 Hive 样式分区的精髓。
现在我们有了文件夹,我们将使用 write_parquet() 为三个子集中的每一个创建一个单独的 parquet 文件。
write_parquet(df_a, file.path(ds_dir_a, "part-0.parquet"))
write_parquet(df_b, file.path(ds_dir_b, "part-0.parquet"))
write_parquet(df_c, file.path(ds_dir_c, "part-0.parquet"))如果愿意,我们可以进一步细分数据集。如果需要,一个文件夹可以包含多个文件(part-0.parquet、part-1.parquet 等)。同样,将文件命名为 part-0.parquet 也没有任何特殊原因:如果愿意,将这些文件命名为 subset-a.parquet、subset-b.parquet 和 subset-c.parquet 也可以。如果需要,我们可以写入其他文件格式,而且不一定非要使用 Hive 样式文件夹。您可以通过阅读 open_dataset() 的帮助文档来了解支持的格式,并通过 help("Dataset", package = "arrow") 了解如何进行细粒度控制。
无论如何,我们已经使用 Hive 样式分区创建了一个磁盘上的 parquet 数据集。我们的数据集由这些文件定义。
list.files(ds_dir, recursive = TRUE)## [1] "subset=a/part-0.parquet" "subset=b/part-0.parquet"
## [3] "subset=c/part-0.parquet"为了验证一切是否正常,我们用 open_dataset() 打开数据并调用 glimpse() 来检查其内容。
ds <- open_dataset(ds_dir)
glimpse(ds)## FileSystemDataset with 3 Parquet files
## 15 rows x 3 columns
## $ id <int32> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15
## $ value <double> -1.400043517, 0.255317055, -2.437263611, -0.005571287, 0.62155~
## $ subset <string> "a", "a", "a", "a", "a", "b", "b", "b", "b", "b", "c", "c", "c~
## Call `print()` for full schema details正如你所看到的,ds Dataset 对象聚合了三个独立的数据文件。事实上,在这个特殊情况下,Dataset 太小了,以至于所有三个文件中的值都出现在 glimpse() 的输出中。
需要注意的是,在日常数据分析工作中,您不需要以这种方式手动写入数据文件。上面的示例完全是为了说明目的。完全相同的数据集可以通过以下命令创建:
ds |>
group_by(subset) |>
write_dataset("mini-dataset")事实上,即使 ds 恰好指的是比内存大的数据源,此命令也应该有效,因为 Dataset 功能旨在确保在此类管道中数据分段加载以避免内存耗尽。
数据集对象
在上一节中,我们检查了数据集的磁盘结构。现在我们转向数据集对象本身(即上一示例中的 ds)的内存结构。创建数据集对象时,arrow 会搜索数据集文件夹以查找适当的文件,但不会加载这些文件的内容。这些文件的路径存储在活动绑定 ds$files 中。
ds$files## [1] "/build/r/vignettes/mini-dataset/subset=a/part-0.parquet"
## [2] "/build/r/vignettes/mini-dataset/subset=b/part-0.parquet"
## [3] "/build/r/vignettes/mini-dataset/subset=c/part-0.parquet"当调用 open_dataset() 时发生的另一件事是,为 Dataset 构建并存储了一个显式 Schema 作为 ds$schema。
ds$schema## Schema
## id: int32
## value: double
## subset: string
##
## See $metadata for additional Schema metadata默认情况下,此 Schema 仅通过检查第一个文件来推断,尽管可以在检查所有文件后构建统一 Schema。为此,在调用 open_dataset() 时将 unify_schemas = TRUE 设置为 TRUE。也可以使用 open_dataset() 的 schema 参数显式指定 Schema(有关详细信息,请参阅 schema() 函数)。
数据的读取由 Scanner 对象执行。在使用 dplyr 界面分析数据集时,您无需手动构建 Scanner,但出于解释目的,我们将在此处进行构建。
scan <- Scanner$create(dataset = ds)调用 ToTable() 方法将把(磁盘上的)数据集具化为(内存中的)表。
scan$ToTable()## Table
## 15 rows x 3 columns
## $id <int32>
## $value <double>
## $subset <string>
##
## See $metadata for additional Schema metadata此扫描过程默认是多线程的,但如有必要,可以通过在调用 Scanner$create() 时将 use_threads = FALSE 设置为 FALSE 来禁用线程。
查询数据集
当对 Dataset 执行查询时,会启动新的扫描并将结果拉回 R。例如,考虑以下 dplyr 表达式:
ds |>
filter(value > 0) |>
mutate(new_value = round(100 * value)) |>
select(id, subset, new_value) |>
collect()## # A tibble: 6 x 3
## id subset new_value
## <int> <chr> <dbl>
## 1 2 a 26
## 2 5 a 62
## 3 6 b 115
## 4 12 c 63
## 5 13 c 207
## 6 15 c 51我们可以通过在 Scanner$create() 中指定 filter 和 projection 参数来创建新的扫描,从而使用低级 Dataset 界面复制此操作。要使用这些参数,您需要了解一些 Arrow 表达式,为此您可能会发现阅读 help("Expression", package = "arrow") 中的帮助文档很有用。
下面定义的扫描器模仿了上面显示的 dplyr 管道,
scan <- Scanner$create(
dataset = ds,
filter = Expression$field_ref("value") > 0,
projection = list(
id = Expression$field_ref("id"),
subset = Expression$field_ref("subset"),
new_value = Expression$create("round", 100 * Expression$field_ref("value"))
)
)如果我们调用 as.data.frame(scan$ToTable()),它将产生与 dplyr 版本相同的结果,尽管行可能不会以相同的顺序出现。
为了更好地了解查询执行时发生的情况,我们在此处调用 scan$ScanBatches()。与 ToTable() 方法非常相似,ScanBatches() 方法针对每个文件单独执行查询,但它返回一个 Record Batch 列表,每个文件一个。此外,我们将这些 Record Batch 逐个转换为数据框。
lapply(scan$ScanBatches(), as.data.frame)## [[1]]
## id subset new_value
## 1 2 a 26
## 2 5 a 62
##
## [[2]]
## id subset new_value
## 1 6 b 115
##
## [[3]]
## id subset new_value
## 1 12 c 63
## 2 13 c 207
## 3 15 c 51如果我们回到之前进行的 dplyr 查询,并使用 compute() 返回一个 Table,而不是使用 collect() 返回一个数据框,我们就可以看到这个过程的证据。Table 对象是通过连接查询针对三个数据文件执行时产生的三个 Record Batch 创建的,因此定义 Table 列的 Chunked Array 反映了数据文件中存在的分区结构。
tbl <- ds |>
filter(value > 0) |>
mutate(new_value = round(100 * value)) |>
select(id, subset, new_value) |>
compute()
tbl$subset## ChunkedArray
## <string>
## [
## [
## "a",
## "a"
## ],
## [
## "b"
## ],
## [
## "c",
## "c",
## "c"
## ]
## ]附加说明
前面讨论中忽略的一个区别是
FileSystemDataset和InMemoryDataset对象之间的区别。在通常情况下,构成数据集的数据存储在磁盘文件中。毕竟,这是数据集相对于表的主要优势。然而,在某些情况下,从已存储在内存中的数据创建数据集可能很有用。在这种情况下,创建的对象将具有InMemoryDataset类型。前面的讨论假设存储在数据集中所有文件都具有相同的 Schema。在通常情况下这是正确的,因为每个文件在概念上都是单个矩形表的子集。但这并非严格要求。
有关这些主题的更多信息,请参阅 help("Dataset", package = "arrow")。