本文描述了 Arrow 数据对象的内部结构。Arrow R 包的用户通常不需要理解 Arrow 数据对象的内部结构。我们在此提供此信息,以帮助那些希望理解 Arrow 规范的 R 用户和 Arrow 开发者。本文对 数据对象文章中描述的一些主题进行了更深入的探讨,主要面向开发者。对于使用 arrow 包而言,这不是必要的知识。
我们首先描述两个关键概念
- 数组中的值存储在一个或多个缓冲区中。缓冲区是具有给定长度的连续虚拟地址空间(即内存块)。给定一个指定缓冲区起始内存地址的指针,您可以使用“偏移量”值(指定相对于缓冲区起始位置的位置)访问缓冲区中的任何字节。
- 数组的物理布局是一个术语,用于描述数组中的数据在内存中的排列方式,而不考虑如何解释这些信息。例如:32 位有符号整数和 32 位浮点数具有相同的布局:它们都是 32 位,在内存中表示为 4 个连续字节。它们的含义不同,但布局相同。
我们可以使用一个简单的整数值数组来解开这些概念
integer_array <- Array$create(c(1L, NA, 2L, 4L, 8L))
integer_array## Array
## <int32>
## [
## 1,
## null,
## 2,
## 4,
## 8
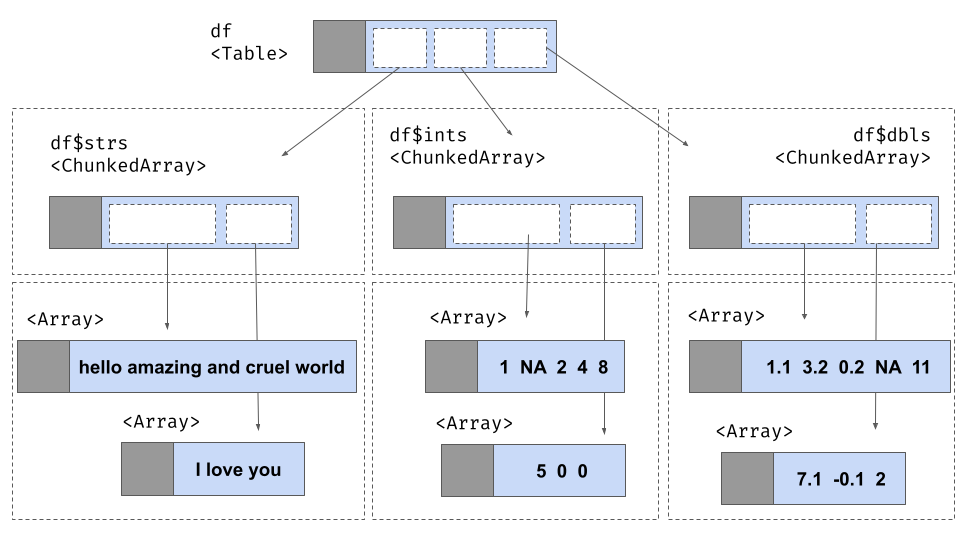
## ]我们可以检查 integer_array$type 属性,查看数组中的值是作为有符号 32 位整数存储的。当由 Arrow C++ 库在内存中布局时,整数数组由两部分元数据和两个存储数据的缓冲区组成。元数据指定数组的长度和空值数量,两者都存储为 64 位整数。这些元数据可以分别通过 R 中的 integer_array$length() 和 integer_array$null_count 查看。与数组关联的缓冲区数量取决于所存储数据的确切类型。对于整数数组,有两个缓冲区:“有效性位图缓冲区”和“数据值缓冲区”。我们可以示意性地将数组描绘如下
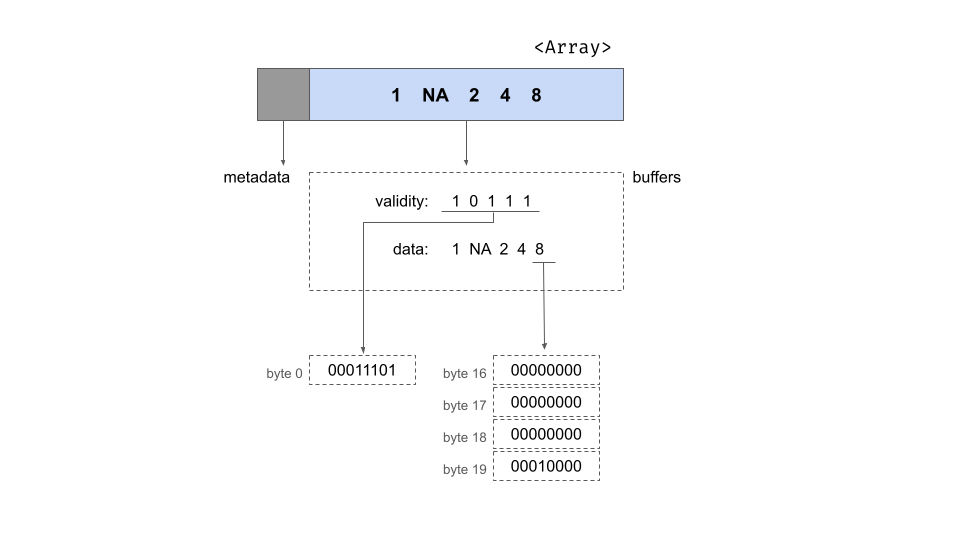
此图像将数组显示为一个矩形,分为两部分,一部分用于元数据,另一部分用于缓冲区。在矩形下方,我们为您解包了缓冲区的内容,在虚线框内显示了两个缓冲区的内容。在图的最底部,您可以看到特定字节的内容。
有效性位图缓冲区
有效性位图是二进制值的,当数组中相应的槽位包含有效、非空值时,它包含 1。在抽象层面,我们可以假设它包含以下五个位
10111然而,这在三个方面略微简化了。首先,由于内存以字节大小的单位分配,末尾有三个尾随位(假定为零),这给了我们位图 10111000。其次,虽然我们是从左到右书写,但这种书写格式通常假定表示 大端格式,其中最高有效位首先写入(即写入最低值的内存地址)。Arrow 采用小端约定,这在用英语书写时更自然地对应于从右到左的顺序。为了反映这一点,我们以从右到左的顺序书写位:00011101。最后,Arrow 鼓励 自然对齐的数据结构,其中分配的内存地址是数据块大小的倍数。Arrow 使用64 字节对齐,因此每个数据结构的大小必须是 64 字节的倍数。此设计特性旨在有效利用现代硬件,如 Arrow 规范中所述。这就是缓冲区在内存中的样子
| 字节 0(有效性位图) | 字节 1-63 |
|---|---|
00011101 |
0(填充) |
数据缓冲区
数据缓冲区,像有效性位图一样,填充到 64 字节的长度以保持自然对齐。这是显示物理布局的图表
| 字节 0-3 | 字节 4-7 | 字节 8-11 | 字节 12-15 | 字节 16-19 | 字节 20-63 |
|---|---|---|---|---|---|
1 |
未指定 | 2 |
4 |
8 |
未指定 |
每个整数占用 4 个字节,符合 32 位有符号整数的要求。请注意,与缺失值关联的字节未指定:为该值分配了空间,但这些字节未填充。
偏移量缓冲区
某些类型的 Arrow 数组包含一个称为偏移量缓冲区的第三个缓冲区。这最常在字符串数组的上下文中遇到,例如这个
string_array <- Array$create(c("hello", "amazing", "and", "cruel", "world"))
string_array## Array
## <string>
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ]使用与以前相同的示意表示法,这是对象的结构。它具有与以前相同的元数据,但如下所示,现在有三个缓冲区
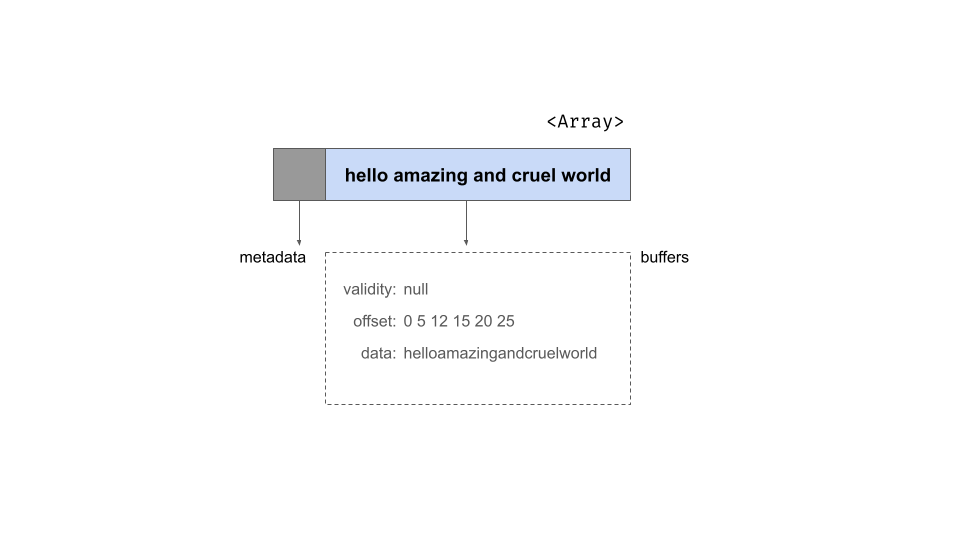
为了理解偏移量缓冲区的作用,了解字符串数组的数据缓冲区格式很有帮助:它将所有字符串首尾相连地连接在内存的一个连续区域中。对于 string_array 对象,数据缓冲区的内容看起来像一个长长的 UTF8 编码字符串
helloamazingandcruelworld由于单个字符串的长度可能不同,偏移量缓冲区的作用是指定槽位之间的边界。我们数组中的第二个槽位是字符串 "amazing"。如果数据数组中的位置按以下方式索引
| h | e | l | l | o | a | m | a | z | i | n | g | a | n | d | … |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | … |
那么我们可以看到感兴趣的字符串从位置 5 开始到位置 11 结束。偏移量缓冲区由存储这些断点位置的整数组成。对于 string_array,它可能看起来像这样
0 5 12 15 20 25utf8() 数据类型和 large_utf8() 数据类型之间的区别在于,utf8() 数据类型将它们存储为 32 位整数,而 large_utf8() 类型将它们存储为 64 位整数。
分块数组
数组是不可变对象:一旦数组初始化,它存储的值就不能更改。这确保了多个实体可以通过指针安全地引用数组,而不会有值更改的风险。使用不可变数组使得 Arrow 能够避免不必要的数据对象复制。
不可变数组存在局限性,尤其是在新批数据到达时。由于数组是不可变的,您无法将新信息添加到现有数组中。如果您不想干扰或复制现有数组,唯一能做的就是创建一个包含新数据的新数组。这样做保留了数组的不可变性,并且不会导致任何不必要的复制,但现在我们有一个新问题:数据分布在两个数组中。每个数组只包含一个数据“块”。理想情况是有一个抽象层,允许我们将这两个数组视为一个单一的“类数组”对象。
这就是分块数组解决的问题。分块数组是数组列表的包装器,允许您“如同”它们是单个数组一样索引其内容。物理上,数据仍然存储在不同的位置——每个数组是一个块,这些块在内存中不必彼此相邻——但分块数组为我们提供了一个抽象层,允许我们假装它们都是一个整体。
为了说明,让我们使用 chunked_array() 函数
chunked_string_array <- chunked_array(
c("hello", "amazing", "and", "cruel", "world"),
c("I", "love", "you")
)chunked_array() 函数只是 ChunkedArray$create() 功能的包装器。让我们看看这个对象
chunked_string_array## ChunkedArray
## <string>
## [
## [
## "hello",
## "amazing",
## "and",
## "cruel",
## "world"
## ],
## [
## "I",
## "love",
## "you"
## ]
## ]此输出中的双括号旨在突出分块数组的“列表状”特性。有三个独立的数组,包装在一个实际上是数组列表的容器对象中,但允许该列表像普通的一维数据结构一样运行。示意图如下所示
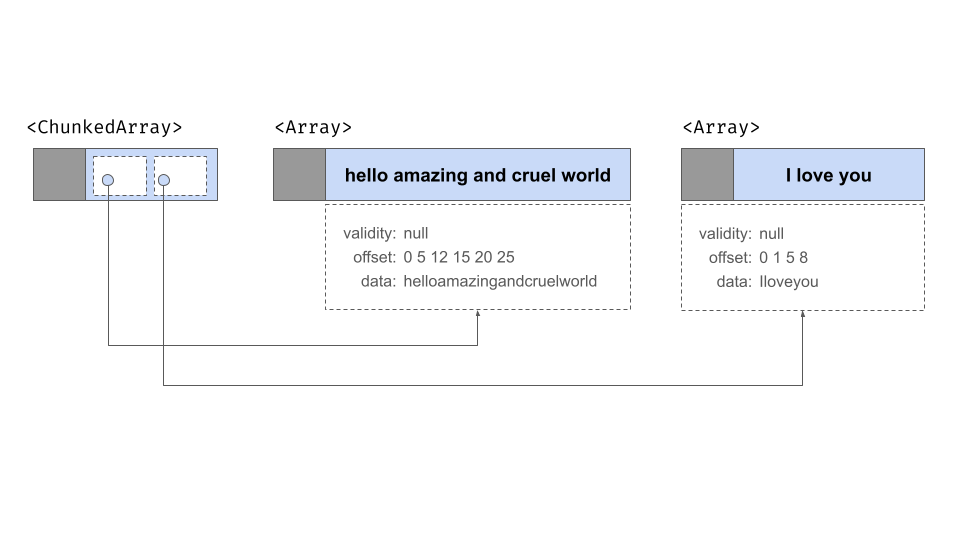
如图所示,这里确实有三个数组,每个数组都有自己的有效性位图、偏移量缓冲区和数据缓冲区。
记录批次
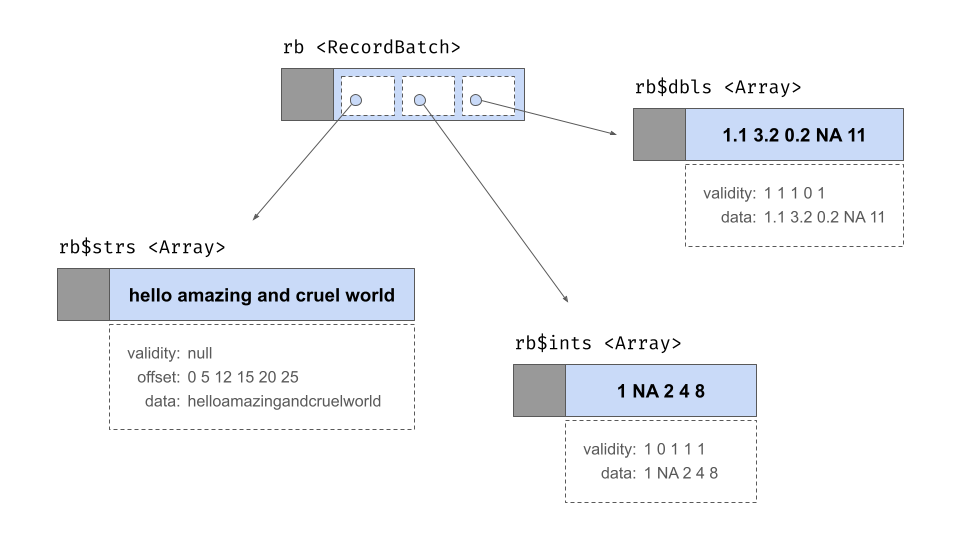
记录批次是类似于表的结构,由一系列数组组成。数组可以是不同类型的,但它们都必须具有相同的长度。每个数组都被称为记录批次的“字段”或“列”之一。每个字段都必须有一个(UTF8 编码的)名称,这些名称构成了记录批次元数据的一部分。当存储在内存中时,记录批次不包含存储在每个字段中的值的物理存储:相反,它包含指向相关数组对象的指针。但是,它确实包含自己的有效性位图。
这是一个包含 5 行 3 列的记录批次
rb <- record_batch(
strs = c("hello", "amazing", "and", "cruel", "world"),
ints = c(1L, NA, 2L, 4L, 8L),
dbls = c(1.1, 3.2, 0.2, NA, 11)
)
rb## RecordBatch
## 5 rows x 3 columns
## $strs <string>
## $ints <int32>
## $dbls <double>在抽象层面,rb 对象表现为具有行和列的二维结构,但就其在内存中的表示方式而言,它本质上是一个数组列表,如下所示
表
为了处理矩形数据集随时间增长(随着更多数据添加)的情况,我们需要一个类似于记录批次的表格数据结构,但有一个例外:我们现在希望将每列存储为分块数组,而不是存储为数组。这就是 arrow 中 Table 类所做的。
为了说明,假设我们有第二组数据,它以记录批次的形式到达
new_rb <- record_batch(
strs = c("I", "love", "you"),
ints = c(5L, 0L, 0L),
dbls = c(7.1, -0.1, 2)
)
df <- concat_tables(arrow_table(rb), arrow_table(new_rb))
df## Table
## 8 rows x 3 columns
## $strs <string>
## $ints <int32>
## $dbls <double>这是此表的基础结构