Arrow 有一个丰富的数据类型系统,其中包括许多 R 数据类型的直接对应物,以及许多在 R 中没有对应物的数据类型。本文描述了 Arrow 类型系统,将其与 R 数据类型进行比较,并概述了数据从 Arrow 传输到 R 时使用的默认映射。文章末尾有两个查找表:一个描述默认的“R 到 Arrow”类型映射,另一个描述“Arrow 到 R”映射。
动机示例
为了说明需要进行的转换,请考虑当我们使用 dplyr::glimpse() 检查原始格式的 starwars 数据(作为 R 中的数据框)时获得的输出,以及我们通过调用 arrow_table() 先将其转换为 Arrow Table 时获得的输出之间的差异。
## Rows: 87
## Columns: 14
## $ name <chr> "Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia Or~
## $ height <int> 172, 167, 96, 202, 150, 178, 165, 97, 183, 182, 188, 180, 2~
## $ mass <dbl> 77.0, 75.0, 32.0, 136.0, 49.0, 120.0, 75.0, 32.0, 84.0, 77.~
## $ hair_color <chr> "blond", NA, NA, "none", "brown", "brown, grey", "brown", N~
## $ skin_color <chr> "fair", "gold", "white, blue", "white", "light", "light", "~
## $ eye_color <chr> "blue", "yellow", "red", "yellow", "brown", "blue", "blue",~
## $ birth_year <dbl> 19.0, 112.0, 33.0, 41.9, 19.0, 52.0, 47.0, NA, 24.0, 57.0, ~
## $ sex <chr> "male", "none", "none", "male", "female", "male", "female",~
## $ gender <chr> "masculine", "masculine", "masculine", "masculine", "femini~
## $ homeworld <chr> "Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan", "T~
## $ species <chr> "Human", "Droid", "Droid", "Human", "Human", "Human", "Huma~
## $ films <list> <"A New Hope", "The Empire Strikes Back", "Return of the J~
## $ vehicles <list> <"Snowspeeder", "Imperial Speeder Bike">, <>, <>, <>, "Imp~
## $ starships <list> <"X-wing", "Imperial shuttle">, <>, <>, "TIE Advanced x1",~glimpse(arrow_table(starwars))## Table
## 87 rows x 14 columns
## $ name <string> "Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia~
## $ height <int32> 172, 167, 96, 202, 150, 178, 165, 97, 183, 182, 188, 180~
## $ mass <double> 77.0, 75.0, 32.0, 136.0, 49.0, 120.0, 75.0, 32.0, 84.0, ~
## $ hair_color <string> "blond", NA, NA, "none", "brown", "brown, grey", "brown"~
## $ skin_color <string> "fair", "gold", "white, blue", "white", "light", "light"~
## $ eye_color <string> "blue", "yellow", "red", "yellow", "brown", "blue", "blu~
## $ birth_year <double> 19.0, 112.0, 33.0, 41.9, 19.0, 52.0, 47.0, NA, 24.0, 57.~
## $ sex <string> "male", "none", "none", "male", "female", "male", "femal~
## $ gender <string> "masculine", "masculine", "masculine", "masculine", "fem~
## $ homeworld <string> "Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan",~
## $ species <string> "Human", "Droid", "Droid", "Human", "Human", "Human", "H~
## $ films <list<...>> <"A New Hope", "The Empire Strikes Back", "Return of the~
## $ vehicles <list<...>> <"Snowspeeder", "Imperial Speeder Bike">, <>, <>, <>, "I~
## $ starships <list<...>> <"X-wing", "Imperial shuttle">, <>, <>, "TIE Advanced x1~
## Call `print()` for full schema details所表示的数据本质上是相同的,但列的数据类型描述已更改。例如:
-
数据框中的
name标记为<chr>(字符向量);在 Arrow 表中标记为<string>(字符串类型,也称为 utf8 类型) -
数据框中的
height标记为<int>(整数向量);在 Arrow 表中标记为<int32>(32 位有符号整数) -
数据框中的
mass标记为<dbl>(数值向量);在 Arrow 表中标记为<double>(64 位浮点数)
其中一些差异纯粹是表面上的:R 中的整数实际上是 32 位有符号整数,因此 Arrow 和 R 中底层数据类型是相互直接对应的。在其他情况下,差异纯粹是关于实现:Arrow 和 R 存储字符串向量的方式不同,但在高层次的抽象下,R 字符类型和 Arrow 字符串类型可以被视为直接对应物。然而,在某些情况下,没有明确的对应物:虽然 Arrow 有 POSIXct(时间戳类型)的对应物,但它没有 POSIXlt 的对应物;反之,虽然 R 可以表示 32 位有符号整数,但它没有 64 位无符号整数的等价物。
当 arrow 包在 R 数据和 Arrow 数据之间进行转换时,它会首先检查是否提供了 Schema(有关更多信息,请参见 schema()),如果没有可用,它将尝试通过遵循默认映射来猜测适当的类型。这些映射的完整列表在文章末尾提供,但最常见的案例如下图所示
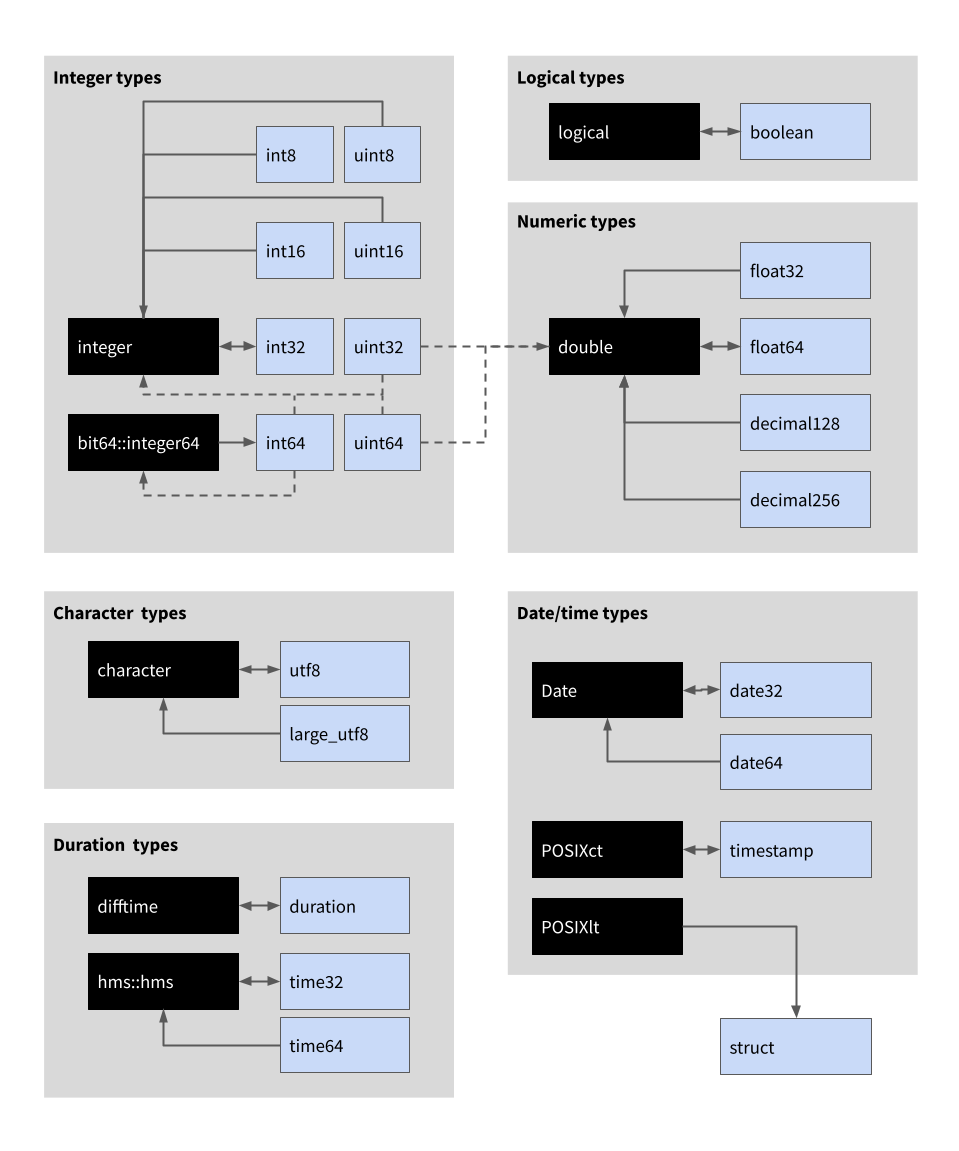
在此图中,黑色框表示 R 数据类型,浅蓝色框表示 Arrow 数据类型。方向箭头指定转换(例如,逻辑 R 类型和布尔 Arrow 类型之间的双向箭头表示逻辑 R 转换为 Arrow 布尔值,反之亦然)。实线表示此转换规则始终是默认的;虚线表示它有时才适用(规则和特殊情况如下所述)。
逻辑/布尔类型
Arrow 和 R 都使用三值逻辑。在 R 中,逻辑值可以是 TRUE 或 FALSE,NA 用于表示缺失数据。在 Arrow 中,相应的布尔类型可以取值 true、false 或 null,如下所示
chunked_array(c(TRUE, FALSE, NA), type = boolean()) # default## ChunkedArray
## <bool>
## [
## [
## true,
## false,
## null
## ]
## ]在此示例中设置 type = boolean() 并非严格必要,因为 arrow 的默认行为是将 R 逻辑向量转换为 Arrow 布尔值,反之亦然。然而,为了清晰起见,我们将在本文中明确指定数据类型。我们还将使用 chunked_array() 从 R 对象创建 Arrow 数据,并使用 as.vector() 从 Arrow 对象创建 R 数据,但如果使用其他方法,也会得到类似的结果。
整数类型
R 基本类型原生只支持一种整数类型,使用 32 位表示介于 -2147483648 和 2147483647 之间的有符号数,尽管 R 也可以通过 bit64 包支持 64 位整数。Arrow 从 C++ 继承了 8 位、16 位、32 位和 64 位的有符号和无符号整数类型
| 描述 | 数据类型函数 | 最小值 | 最大值 |
|---|---|---|---|
| 8 位无符号 | uint8() |
0 | 255 |
| 16 位无符号 | uint16() |
0 | 65535 |
| 32 位无符号 | uint32() |
0 | 4294967295 |
| 64 位无符号 | uint64() |
0 | 18446744073709551615 |
| 8 位有符号 | int8() |
-128 | 127 |
| 16 位有符号 | int16() |
-32768 | 32767 |
| 32 位有符号 | int32() |
-2147483648 | 2147483647 |
| 64 位有符号 | int64() |
-9223372036854775808 | 9223372036854775807 |
默认情况下,arrow 将 R 整数转换为 Arrow 中的 int32 类型,但您可以通过明确指定另一个整数类型来覆盖此行为
chunked_array(c(10L, 3L, 200L), type = int32()) # default## ChunkedArray
## <int32>
## [
## [
## 10,
## 3,
## 200
## ]
## ]chunked_array(c(10L, 3L, 200L), type = int64())## ChunkedArray
## <int64>
## [
## [
## 10,
## 3,
## 200
## ]
## ]如果 R 中的值超出相应 Arrow 类型的允许范围,arrow 将抛出错误
chunked_array(c(10L, 3L, 200L), type = int8())## Error: Invalid: value outside of range当从 Arrow 转换为 R 时,整数类型始终转换为 R 整数,除非适用以下例外情况之一
- 如果 Arrow uint32 或 uint64 的值超出 R 整数允许的范围,结果将是 R 中的数值向量
- 如果 Arrow int64 变量的值超出 R 整数允许的范围,结果将是 R 中的
bit64::integer64向量 - 如果用户设置
options(arrow.int64_downcast = FALSE),无论值如何,Arrow int64 类型始终在 R 中生成bit64::integer64向量
浮点数值类型
R 有一个双精度(64 位)数值类型,默认情况下转换为 Arrow 64 位浮点类型。Arrow 支持单精度(32 位)和双精度(64 位)浮点数,使用 float32() 和 float64() 数据类型函数指定。这两者都转换为 R 中的双精度浮点数。示例如下
chunked_array(c(0.1, 0.2, 0.3), type = float64()) # default## ChunkedArray
## <double>
## [
## [
## 0.1,
## 0.2,
## 0.3
## ]
## ]chunked_array(c(0.1, 0.2, 0.3), type = float32())## ChunkedArray
## <float>
## [
## [
## 0.1,
## 0.2,
## 0.3
## ]
## ]arrow_double <- chunked_array(c(0.1, 0.2, 0.3), type = float64())
as.vector(arrow_double)## [1] 0.1 0.2 0.3请注意,Arrow 规范还允许半精度(16 位)浮点数,但这些尚未实现。
定点十进制类型
Arrow 还包含 decimal() 数据类型,其中数值以十进制而不是二进制格式指定。Arrow 中的十进制数有两种,128 位版本和 256 位版本,但在大多数情况下,用户应该能够使用更通用的 decimal() 数据类型函数,而不是特定的 decimal32()、decimal64()、decimal128() 和 decimal256() 函数。
Arrow 中的十进制类型是定精度数字(而不是浮点数),这意味着需要明确指定 precision 和 scale 参数
-
precision指定要存储的有效数字位数。 -
scale指定小数点后应存储的位数。如果将scale = 2,则小数点后将精确存储两位数。如果将scale = 0,值将四舍五入到最接近的整数。也允许负刻度(处理极大数字时很方便),因此scale = -2将值存储到最接近的 100。
由于 R 没有本地创建十进制类型的方法,下面的示例有点迂回。首先,我们创建一些浮点数作为 Chunked Arrays,然后在 Arrow 中将它们显式转换为十进制类型。这是可能的,因为 Chunked Array 对象具有 cast() 方法
arrow_floating <- chunked_array(c(.01, .1, 1, 10, 100))
arrow_decimals <- arrow_floating$cast(decimal(precision = 5, scale = 2))
arrow_decimals## ChunkedArray
## <decimal32(5, 2)>
## [
## [
## 0.01,
## 0.10,
## 1.00,
## 10.00,
## 100.00
## ]
## ]尽管在 R 中不常用,但十进制类型在特别重要的情况下非常有用,可以避免浮点算术中出现的问题。
字符串/字符类型
R 使用单一字符类型来表示字符串,而 Arrow 有两种类型。在 Arrow C++ 库中,这些类型被称为 strings 和 large_strings,但为了避免 arrow R 包中的歧义,它们使用 utf8() 和 large_utf8() 数据类型函数定义。这两种 Arrow 类型之间的区别对于 R 用户来说可能不重要,尽管在关于 数据对象布局 的文章中讨论了这种差异。
默认行为是将 R 字符向量转换为 utf8/string 类型,并将两种 Arrow 类型都转换为 R 字符向量
strings <- chunked_array(c("oh", "well", "whatever"))
strings## ChunkedArray
## <string>
## [
## [
## "oh",
## "well",
## "whatever"
## ]
## ]as.vector(strings)## [1] "oh" "well" "whatever"因子/字典类型
Arrow 中 R 因子的对应物是字典类型。因子转换为字典,反之亦然。为了说明这一点,让我们在 R 中创建一个小因子对象
## [1] cat dog pig dog
## Levels: cat dog pig当转换为 Arrow 时,结果是这个字典
dict <- chunked_array(fct, type = dictionary())
dict## ChunkedArray
## <dictionary<values=string, indices=int32>>
## [
##
## -- dictionary:
## [
## "cat",
## "dog",
## "pig"
## ]
## -- indices:
## [
## 0,
## 1,
## 2,
## 1
## ]
## ]当转换回 R 时,我们恢复了原始因子
as.vector(dict)## [1] cat dog pig dog
## Levels: cat dog pigArrow 字典比 R 因子稍微灵活一些:字典中的值不一定必须是字符串,但因子中的标签必须是字符串。因此,当转换为 R 时,Arrow 字典中的非字符串值会被强制转换为字符串。
日期类型
在 R 中,日期通常使用 Date 类表示。在内部,Date 对象是一个数值类型,其值计算自 Unix 纪元(1970 年 1 月 1 日)以来的天数。Arrow 提供两种可用于表示日期的数据类型:date32 类型和 date64 类型。date32 类型类似于 R 中的 Date 类:在内部,它存储一个 32 位整数,计算自 1970 年 1 月 1 日以来的天数。arrow 的默认设置是将 R Date 对象转换为 Arrow date32 类型
## [1] "1989-06-15" "1991-09-24" "1993-09-13"nirvana_32 <- chunked_array(nirvana_album_dates, type = date32()) # default
nirvana_32## ChunkedArray
## <date32[day]>
## [
## [
## 1989-06-15,
## 1991-09-24,
## 1993-09-13
## ]
## ]Arrow 还提供了一种高精度 date64 类型,其中日期表示为 64 位整数,编码自 1970-01-01 00:00 UTC 以来的毫秒数
nirvana_64 <- chunked_array(nirvana_album_dates, type = date64())
nirvana_64## ChunkedArray
## <date64[ms]>
## [
## [
## 1989-06-15,
## 1991-09-24,
## 1993-09-13
## ]
## ]从 Arrow 到 R 的转换有所不同。在内部,date32 类型与 R Date 非常相似,因此这些对象在转换为 R 时为 Dates
## [1] "Date"然而,由于 date64 类型指定到毫秒级精度,它们在转换为 R 时为 POSIXct 时间,以避免丢失相关信息的可能性
## [1] "POSIXct" "POSIXt"时间/时间戳类型
在 R 中,有两种类用于表示日期和时间信息,POSIXct 和 POSIXlt。Arrow 只有一种:时间戳类型。Arrow 时间戳与 POSIXct 类大致相似。在内部,POSIXct 对象将日期表示为一个数值变量,该变量存储自 1970-01-01 00:00 UTC 以来的秒数。在内部,Arrow 时间戳是一个 64 位整数,计算自 1970-01-01 00:00 UTC 以来的毫秒数。
Arrow 和 R 都支持时区信息,但在打印对象时显示方式不同。在 R 中,本地时间与时区名称一起打印
sydney_newyear <- as.POSIXct("2000-01-01 00:01", tz = "Australia/Sydney")
sydney_newyear## [1] "2000-01-01 00:01:00 AEDT"当转换为 Arrow 时,此 POSIXct 对象变为 Arrow 时间戳对象。然而,在打印时,时间点总是以 UTC 而不是本地时间显示
sydney_newyear_arrow <- chunked_array(sydney_newyear, type = timestamp())
sydney_newyear_arrow## ChunkedArray
## <timestamp[s]>
## [
## [
## 1999-12-31 13:01:00
## ]
## ]然而,时区信息并未丢失,我们可以通过将 sydney_newyear_arrow 对象转换回 R POSIXct 对象来轻松看到这一点
as.vector(sydney_newyear_arrow)## [1] "1999-12-31 13:01:00 UTC"对于 POSIXlt 对象,行为是不同的。在内部,POSIXlt 对象是一个列表,根据各种与人类相关的字段指定“本地时间”。在 Arrow 中没有与此类似的类,因此默认行为是将其转换为 Arrow 列表。
一天中的时间类型
R 基本类型没有独立于日期表示一天中时间的类(即,不可能在不提及特定日期的情况下指定“下午 3 点”),但可以通过 hms 包来完成。在内部,hms 对象始终存储为自 00:00:00 以来的秒数。
Arrow 为此目的提供了两种数据类型。对于 time32 类型,数据存储为 32 位整数,该整数被解释为自 00:00:00 以来的秒数或毫秒数。请注意以下区别
time_of_day <- hms::hms(56, 34, 12)
chunked_array(time_of_day, type = time32(unit = "s"))## ChunkedArray
## <time32[s]>
## [
## [
## 12:34:56
## ]
## ]chunked_array(time_of_day, type = time32(unit = "ms"))## ChunkedArray
## <time32[ms]>
## [
## [
## 12:34:56.000
## ]
## ]time64 对象类似,但使用 64 位整数存储一天中的时间,并且可以以更高的精度表示时间。可以选择微秒 (unit = "us") 或纳秒 (unit = "ns"),如下所示
chunked_array(time_of_day, type = time64(unit = "us"))## ChunkedArray
## <time64[us]>
## [
## [
## 12:34:56.000000
## ]
## ]chunked_array(time_of_day, type = time64(unit = "ns"))## ChunkedArray
## <time64[ns]>
## [
## [
## 12:34:56.000000000
## ]
## ]Arrow 中 time32 和 time64 对象的所有版本都转换为 R 中的 hms 时间。
持续时间类型
时间长度在 R 中表示为 difftime 对象。Arrow 中类似的数据类型是 duration 类型。duration 类型存储为 64 位整数,可以表示秒数(默认,unit = "s")、毫秒数(unit = "ms")、微秒数(unit = "us")或纳秒数(unit = "ns")。为了说明这一点,我们将在 R 中创建一个对应于 278 秒的 difftime
len <- as.difftime(278, unit = "secs")
len## Time difference of 278 secs转换为 Arrow 看起来像这样
chunked_array(len, type = duration(unit = "s")) # default## ChunkedArray
## <duration[s]>
## [
## [
## 278
## ]
## ]chunked_array(len, type = duration(unit = "ns"))## ChunkedArray
## <duration[ns]>
## [
## [
## 278000000000
## ]
## ]无论底层单位如何,Arrow 中的 duration 对象都转换为 R 中的 difftime 对象。
默认转换列表
上面的讨论涵盖了最常见的情况。本节中的两个表提供了 arrow 如何在 R 数据类型和 Arrow 数据类型之间进行转换的更完整列表。在这些表中,带有 - 的条目目前尚未实现。
从 R 到 Arrow 的转换
| 原始 R 类型 | 转换后的 Arrow 类型 |
|---|---|
| 逻辑型 (logical) | 布尔型 (boolean) |
| 整型 (integer) | int32 |
| 双精度型 (“numeric”) | float64 1 |
| 字符型 (character) | utf8 2 |
| 因子型 (factor) | 字典型 (dictionary) |
| 原始型 (raw) | uint8 |
| 日期型 (Date) | date32 |
| POSIXct | 时间戳型 (timestamp) |
| POSIXlt | 结构型 (struct) |
| 数据框 (data.frame) | 结构型 (struct) |
| 列表型 (list) 3 | 列表型 (list) |
| bit64::integer64 | int64 |
| hms::hms | time32 |
| difftime | 持续时间型 (duration) |
| vctrs::vctrs_unspecified | 空 (null) |
1:float64 和 double 在 Arrow C++ 中是相同的概念和数据类型;但是,在 arrow 中只使用 float64(),因为函数 double() 在 R 基本类型中已经存在
2:如果字符向量超过 2GB 字符串,它将被转换为 large_utf8 Arrow 类型
3:只有所有元素类型相同的列表才能转换为 Arrow 列表类型(即某种类型的“列表”)。
从 Arrow 到 R 的转换
| 原始 Arrow 类型 | 转换后的 R 类型 |
|---|---|
| 布尔型 (boolean) | 逻辑型 (logical) |
| int8 | 整型 (integer) |
| int16 | 整型 (integer) |
| int32 | 整型 (integer) |
| int64 | 整数型 (integer) 1 |
| uint8 | 整型 (integer) |
| uint16 | 整型 (integer) |
| uint32 | 整数型 (integer) 1 |
| uint64 | 整数型 (integer) 1 |
| float16 | - 2 |
| float32 | 双精度型 (double) |
| float64 | 双精度型 (double) |
| utf8 | 字符型 (character) |
| large_utf8 | 字符型 (character) |
| 二进制型 (binary) | arrow_binary 3 |
| large_binary | arrow_large_binary 3 |
| fixed_size_binary | arrow_fixed_size_binary 3 |
| date32 | 日期型 (Date) |
| date64 | POSIXct |
| time32 | hms::hms |
| time64 | hms::hms |
| 时间戳型 (timestamp) | POSIXct |
| 持续时间型 (duration) | difftime |
| 十进制型 (decimal) | 双精度型 (double) |
| 字典型 (dictionary) | 因子型 (factor) 4 |
| 列表型 (list) | arrow_list 5 |
| large_list | arrow_large_list 5 |
| fixed_size_list | arrow_fixed_size_list 5 |
| 结构型 (struct) | 数据框 (data.frame) |
| 空 (null) | vctrs::vctrs_unspecified |
| 映射型 (map) | arrow_list 5 |
| union | - 2 |
1:这些整数类型可能包含超出 R 的 integer 类型(32 位有符号整数)范围的值。当它们超出范围时,uint32 和 uint64 将转换为 double(“数值型”),int64 将转换为 bit64::integer64。可以通过设置 options(arrow.int64_downcast = FALSE) 禁用此转换(以便 int64 始终生成 bit64::integer64 向量)。
2:一些 Arrow 数据类型目前没有 R 等效类型,如果强制转换或通过 schema 映射,将引发错误。
3:arrow*_binary 类实现为原始向量的列表。
4:由于 R 因子的限制,Arrow dictionary 值在转换为 R 时,如果它们不是字符串,则会被强制转换为字符串。
5:arrow*_list 类实现为 vctrs_list_of 的子类,其 ptype 属性设置为与值类型的空 Array 转换后的结果。