Apache Arrow 概述
Apache Arrow 是一个多语言工具箱,用于构建处理和传输大型数据集的高性能应用程序。它旨在提高分析算法的性能以及将数据从一个系统或编程语言移动到另一个系统的效率。
Apache Arrow 的一个关键组成部分是其内存中列式格式,这是一种标准化的、与语言无关的规范,用于在内存中表示结构化的、类似表格的数据集。此数据格式具有丰富的数据类型系统(包括嵌套和用户定义的数据类型),旨在支持分析数据库系统、数据帧库等的需求。
列式存储速度快
Apache Arrow 格式允许计算例程和执行引擎在扫描和迭代大数据块时最大限度地提高效率。特别是,连续的列式布局可以使用现代处理器中最新的 SIMD(单指令,多数据)操作实现矢量化。

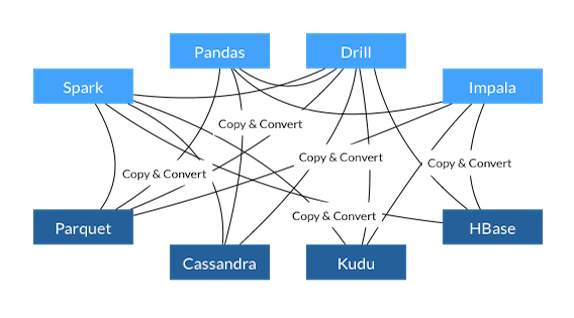
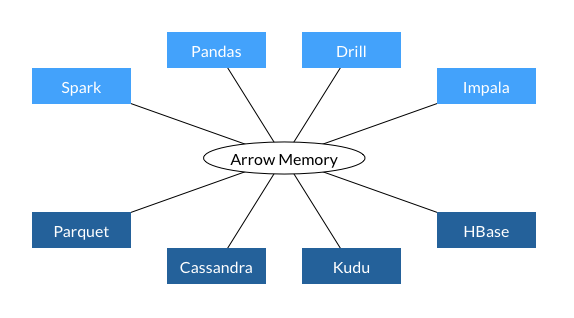
标准化可节省开销
如果没有标准的列式数据格式,每个数据库和语言都必须实现自己的内部数据格式。这会产生大量浪费。将数据从一个系统移动到另一个系统涉及昂贵的序列化和反序列化。此外,通常必须为每种数据格式重写通用算法。
Arrow 的内存中列式数据格式是解决这些问题的开箱即用方案。使用或支持 Arrow 的系统之间可以以极低甚至零成本传输数据。此外,它们不需要为每个其他系统实现自定义连接器。在这些节省的基础上,标准化的内存格式促进了算法库的重用,即使是跨语言的重用。
Arrow 库
Arrow 项目包含的库使您能够使用多种语言处理 Arrow 列式格式的数据。 C++、C#、Go、Java、JavaScript、Julia、Rust 和 Swift 库包含了对 Arrow 格式的不同实现。这些库彼此之间进行了集成测试,以确保它们对格式的忠实度。此外,用于 C (GLib)、MATLAB、Python、R 和 Ruby 的 Arrow 库是构建在 C++ 库之上的。
这些官方库使第三方项目能够使用 Arrow 数据,而无需自己实现 Arrow 列式格式。它们还包含许多软件组件,用于协助解决与从远程存储系统获取数据和将数据移出相关的系统问题,以及通过网络接口移动 Arrow 格式的数据,以及其他用例。