在 Rust 中使用自定义 Thrift 解析器将 Apache Parquet 页脚元数据速度提高 3-9 倍
发布 2025年10月23日
作者 Andrew Lamb (alamb)
编者注:虽然 Apache Arrow 和 Apache Parquet 是独立项目,但 Arrow 的 arrow-rs 存储库托管着 parquet Rust crate 的开发,这是一个广泛使用的高性能 Parquet 实现。
总结
由于新的自定义 Apache Thrift 解析器,parquet Rust crate 的 57.0.0 版本解码元数据的速度比以前的版本快三倍以上。新的解析器在所有情况下都更快,并且能够实现生成解析器无法实现的其他性能改进,例如跳过不必要的字段和选择性解析。
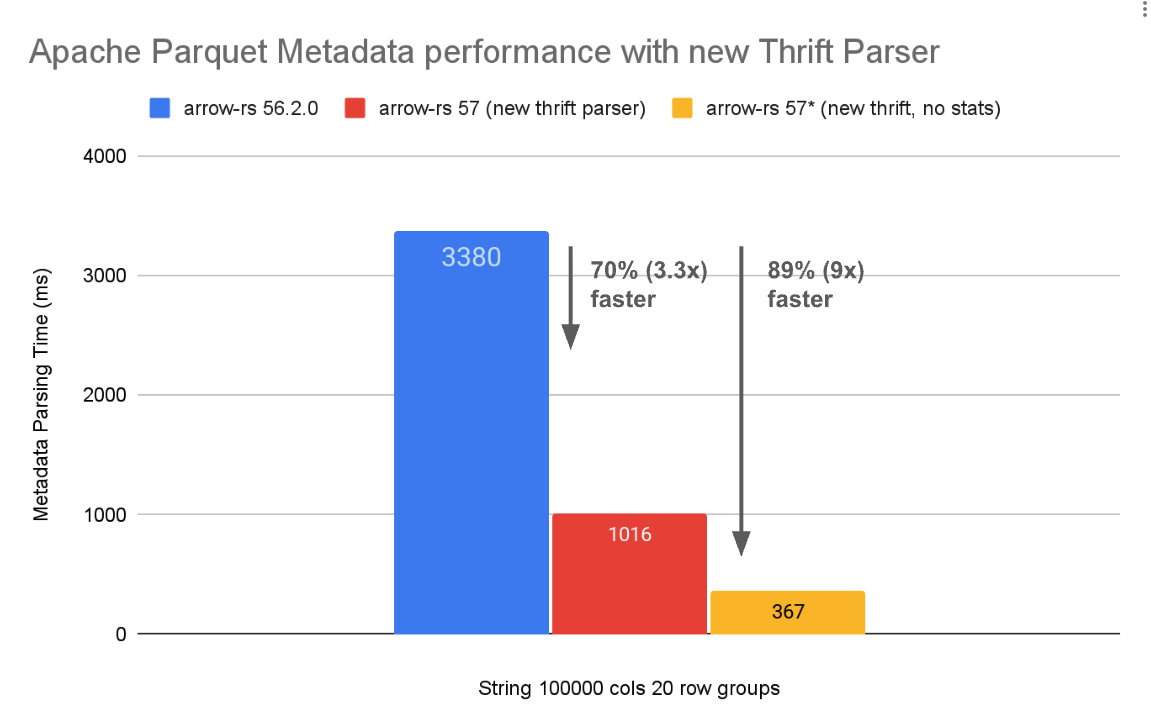
图 1:使用生成 Thrift 解析器(56.2.0 及更早版本)和 arrow-rs 57.0.0 版本中新的 自定义 Thrift 解析器 对 Apache Parquet 元数据解析的性能比较。Parquet 格式本身无需更改。更多详情请参阅 基准测试页面。
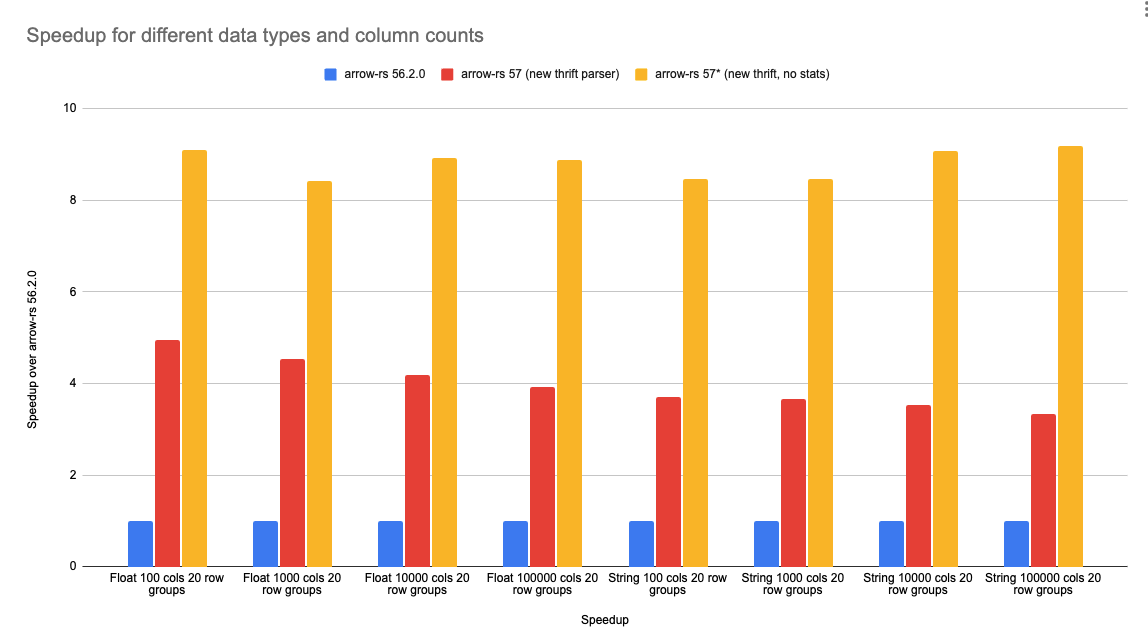
图 2:针对字符串和浮点数据类型,在 100、1000、10,000 和 100,000 列情况下,[自定义 Thrift 解码器] 的加速效果。新解析器在所有情况下都更快,并且加速效果与列数无关。更多详情请参阅 基准测试页面。
介绍:Parquet 和元数据解析的重要性
Apache Parquet 是一种流行的列式存储格式,旨在提高存储和查询处理的效率。Parquet 文件由一系列数据页和页脚组成,如图 3 所示。页脚包含有关文件的元数据,包括模式、统计信息和解码数据页所需的其他信息。
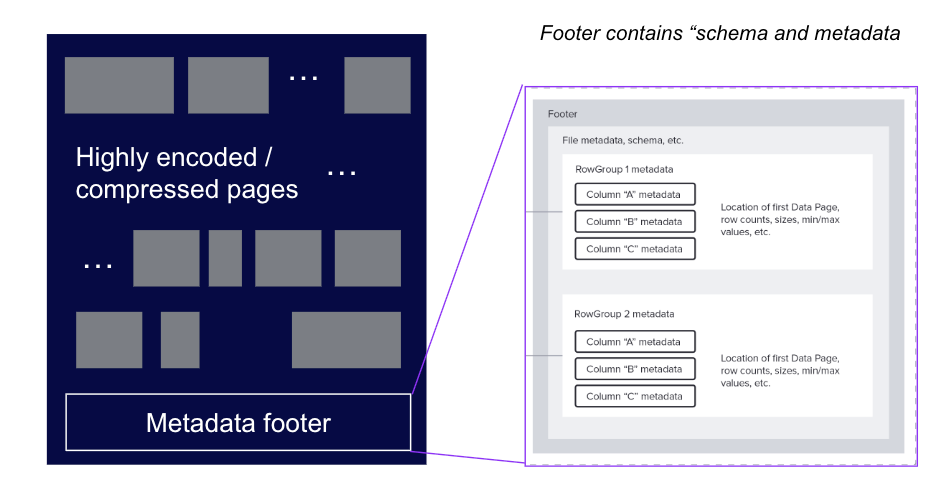
图 3:Parquet 文件的结构,显示了头部、数据页和页脚元数据。
获取存储在页脚中的信息通常是读取 Parquet 文件的第一步,因为它是解释数据页所必需的。解析页脚通常对性能至关重要
- 从快速本地存储(如现代 NVMe SSD)读取时,必须完成页脚解析才能知道要读取哪些数据页,这使其直接位于关键的 I/O 路径上。
- 页脚解析的开销与 Parquet 文件中的列数和行组数呈线性关系,因此对于具有许多列的表或具有许多行组的文件来说,这可能成为瓶颈。
- 即使在将解析后的页脚缓存在内存中的系统中(参见 使用外部索引、元数据存储、目录和缓存来加速 Apache Parquet 上的查询),当缓存未命中时,仍然需要解析页脚。
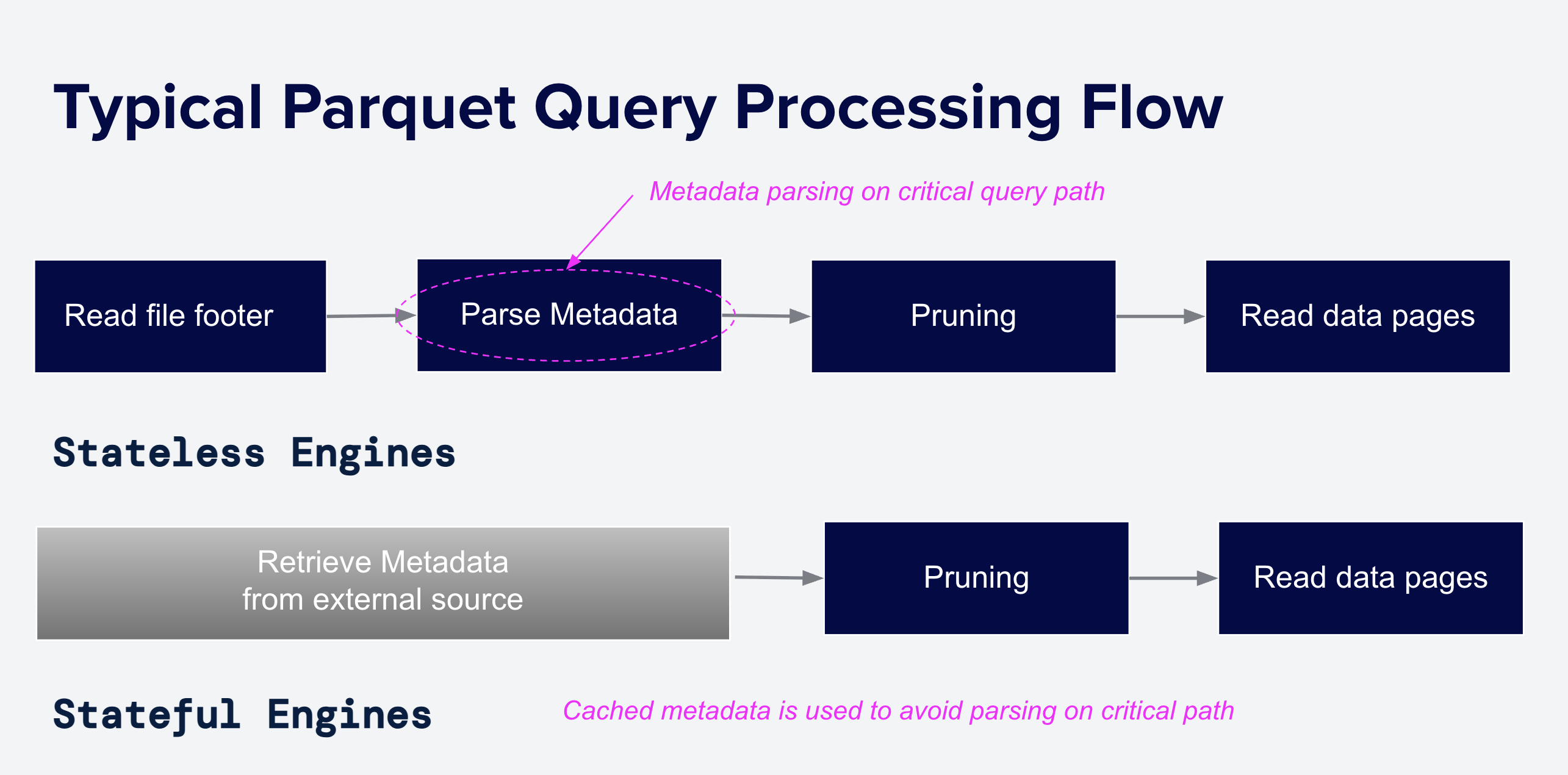
图 4:无状态和有状态系统处理 Parquet 文件的典型流程。无状态引擎在每次查询时读取页脚,因此解析页脚所花费的时间直接增加了查询延迟。有状态系统在查询之前预先缓存部分或全部解析后的页脚。
随着 Parquet 在数据生态系统中的传播,并用于更多对延迟敏感的工作负载,例如可观察性、交互式分析以及为 LLM 供电的检索增强生成 (RAG) 应用程序的单点查找,元数据解析的速度变得越来越重要。随着整体查询时间的减少,花在页脚解析上的比例反而增加了。
背景:Apache Thrift
Parquet 使用 Apache Thrift 存储元数据,Thrift 是一个用于网络数据类型和服务接口的框架。它包含一种类似于 Protocol Buffers 的 数据定义语言。Thrift 定义文件以语言中立的方式描述数据类型,系统通常使用代码生成器自动为特定编程语言创建代码以读取和写入这些数据类型。
parquet.thrift 文件定义了在每个 Parquet 文件末尾以 Thrift Compact 协议 序列化的元数据格式,如图 5 所示。二进制编码是“可变长度”的,这意味着每个元素的长度取决于其内容,而不仅仅是其类型。较小值的基本类型编码使用的字节数少于较大值,字符串和列表以内联方式存储,并带有长度前缀。
这种编码是空间高效的,但由于其可变长度,不支持随机访问:在不扫描所有前面字段的情况下,无法定位特定字段。其他格式,如 FlatBuffers,提供随机访问解析,并因其理论性能优势而 被提议作为替代方案。然而,更改 Parquet 格式是一项艰巨的任务,需要社区和生态系统的支持,并且可能需要数年才能被采用。
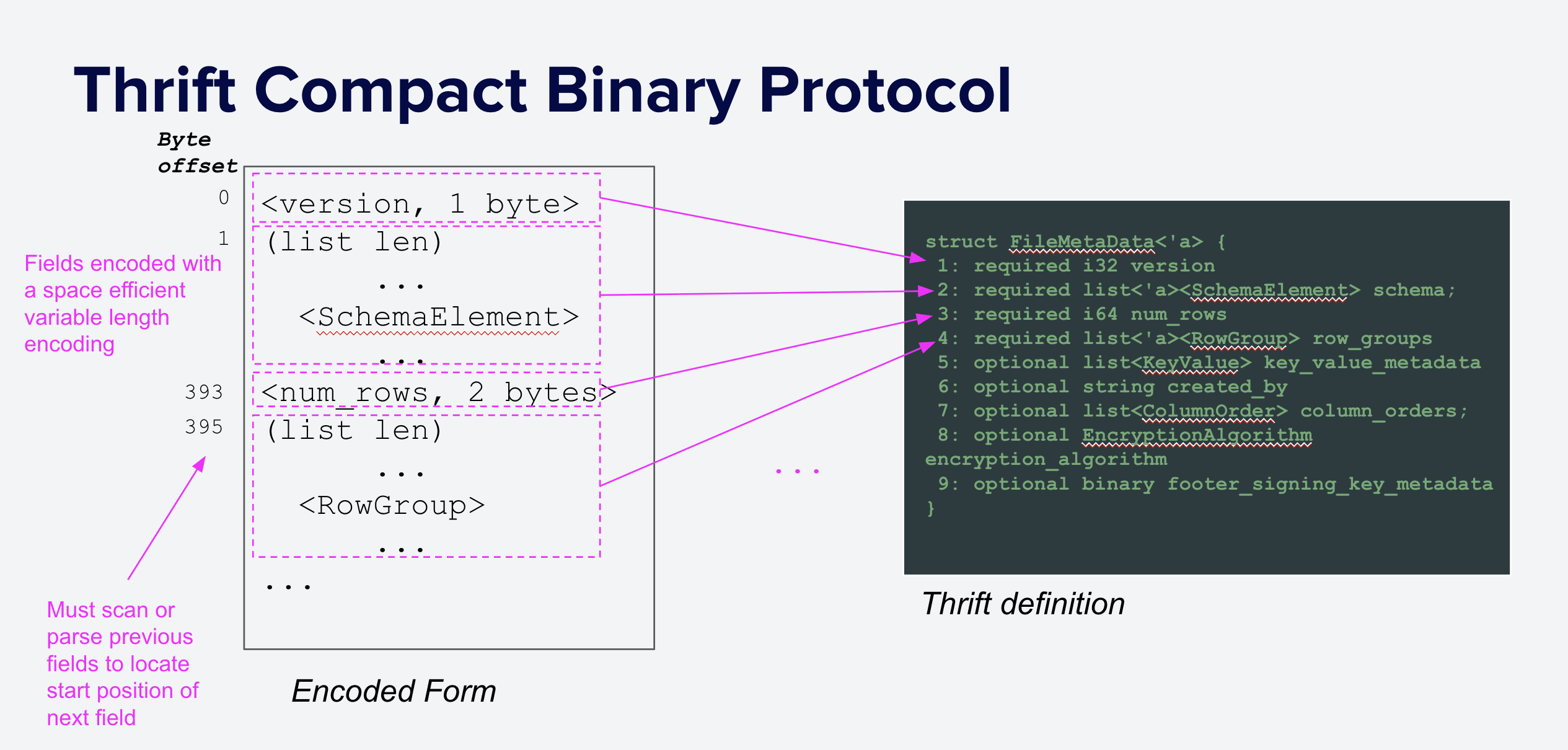
图 5:Parquet 元数据使用 Thrift Compact 协议 序列化。每个字段使用可变数量的字节存储,其数量取决于其值。原始类型使用可变长度编码,字符串和列表带有长度前缀。
尽管 Thrift 由于缺乏随机访问而存在实际缺点,但软件优化比格式更改更容易部署。Xiangpeng Hao 先前的分析推测,仅通过优化 Parquet 页脚解析的实现,就有显著的(2-4 倍)潜在性能改进(更多详情请参阅 Parquet 对宽表(机器学习工作负载)的适用性究竟如何?)。
使用生成解析器处理 Thrift
解析 Parquet 元数据是将 Thrift 编码的字节解码为可用于计算的内存中结构的过程。大多数 Parquet 实现使用现有的 Thrift 编译器 之一生成解析器,将 Thrift 二进制数据转换为生成的代码结构,然后将这些生成结构的相关部分复制到 API 级结构中。例如,C/C++ Parquet 实现 包含一个 两-步 过程,parquet-java 也是如此。DuckDB 也包含一个 Thrift 编译器生成的解析器。
在 56.2.0 及更早版本中,Apache Arrow Rust 实现使用了相同的模式。format 模块包含由 thrift crate 和 parquet.thrift 定义生成的解析器。解析元数据涉及
- 在 Thrift 二进制数据上调用生成的解析器,生成内存中的结构(例如,
struct FileMetaData),然后 - 将相关字段复制到更易于用户使用的表示形式
ParquetMetadata。
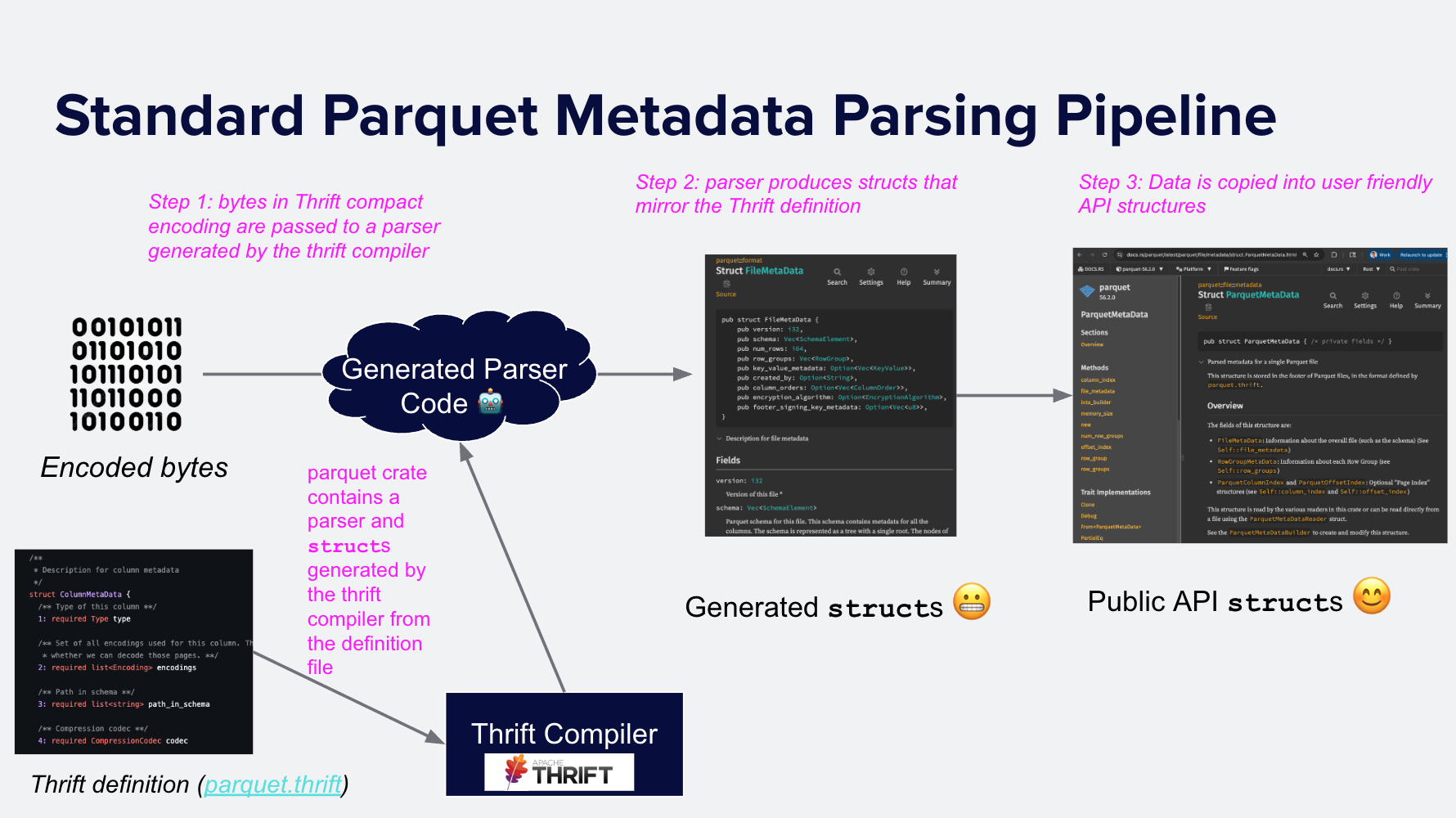
图 6:读取 Parquet 元数据的两步过程:使用 thrift crate 和 parquet.thrift 创建的解析器将元数据字节解析为生成的内存结构。然后,这些结构被转换为 API 对象。
标准 Thrift 编译器生成的解析器通常在一次遍历 Thrift 编码字节时解析所有字段,并将数据复制到内存中的堆分配结构中(例如 Rust Vec 或 C++ std::vector),如下面的图 7 所示。
解析所有字段是直接的,并且鉴于 Thrift 最初设计目标是编码网络消息,这是一个很好的默认选择。网络消息通常不包含与接收方无关的额外信息;然而,Parquet 元数据通常确实包含特定查询不需要的信息。在这种情况下,将整个元数据解析为内存结构是浪费的。
例如,对一个包含 1,000 列的文件进行查询,如果只读取 10 列并有一个单列谓词(例如,time > now() - '1 minute'),则只需要
-
time列的Statistics(或ColumnIndex) -
10 个选定列的
ColumnChunk信息
解析所有统计信息和所有 ColumnChunks 的默认策略(分配和复制)会导致创建比必要多 999 个统计信息和 990 个 ColumnChunks。如上所述,鉴于元数据使用的可变编码,仍然必须获取和扫描所有元数据字节;然而,CPU 扫描数据速度(非常)快,跳过不需要字段的解析显著提高了整体元数据性能。

图 7:生成的 Thrift 解析器通常将编码字节解析为需要许多小的堆分配的结构,这很昂贵。
新设计:自定义 Thrift 解析器
与生成的代码典型情况一样,生成 Thrift 解析器的行为专业化机会有限
- 它不容易修改(当 Thrift 定义更改时会重新生成,并带有警告
/* DO NOT EDIT UNLESS YOU ARE SURE THAT YOU KNOW WHAT YOU ARE DOING */)。 - 它通常与 Thrift 定义一一对应,限制了零拷贝解析、字段跳过和摊销内存分配策略等额外优化。
- 它的 API 非常稳定(难以更改),这对于使用 thrift crate 构建大量项目时轻松维护非常重要。例如,撰写本文时,Rust
thriftcrate 的上次发布 距今已有近三年。
这些限制是 Thrift 项目设计目标的必然结果:易于嵌入到各种其他项目中的通用代码,而不是 Thrift 格式的任何基本限制。鉴于我们快速解析 Parquet 元数据的目标,我们需要一个自定义的、更易于优化的解析器,以将 Thrift 二进制直接转换为所需的结构(图 8)。由于 arrow-rs 已经对生成的代码进行了一些后处理,并包含了一个紧凑协议 API 的自定义实现,因此改为完全自定义的解析器是自然而然的下一步。

图 8:使用自定义 Thrift 解析器进行一步式 Parquet 元数据解析。Thrift 二进制文件直接解析为所需的内存表示,并使用高度优化的代码。
我们新的自定义解析器针对 Parquet 使用的 Thrift 特定子集进行了优化,并包含各种性能优化,例如仔细的内存分配。最大的初始加速来自于移除中间结构并直接创建所需的内存表示。我们还仔细手动优化了几个性能关键的代码路径(参见 #8574、#8587 和 #8599)。
可维护性
自定义解析器最大的问题是其维护难度高于生成的解析器,因为自定义解析器必须随着 parquet.thrift 的任何更改而更新。考虑到对 Parquet 的重新兴起的兴趣以及最近添加的 地理空间 和 变体 类型等新功能,这是一个日益增长的担忧。
令人欣慰的是,经过与社区的讨论,Jörn Horstmann 开发了一种 基于 Rust 宏的方法,用于生成带有注解的 Rust 结构体,这些结构体与 Thrift 定义非常相似,同时允许在必要时进行额外的手动优化。这种方法类似于 serde crate,其中可以使用 #[derive] 注解生成通用实现,并在需要时手动编写专门的序列化。Ed Seidl 随后使用这些宏重写了 parquet crate 中的元数据解析代码。有关所涉及的工作量详情,请参阅 最终 PR。
例如,这是 FileMetaData 结构的原始 Thrift 定义(为简洁起见,省略了注释)
struct FileMetaData {
1: required i32 version
2: required list<SchemaElement> schema;
3: required i64 num_rows
4: required list<RowGroup> row_groups
5: optional list<KeyValue> key_value_metadata
6: optional string created_by
7: optional list<ColumnOrder> column_orders;
8: optional EncryptionAlgorithm encryption_algorithm
9: optional binary footer_signing_key_metadata
}
这里(源)是使用 Thrift 宏的相应 Rust 结构(在 Ed 在 #8574 中编写自定义版本之前)
thrift_struct!(
struct FileMetaData<'a> {
1: required i32 version
2: required list<'a><SchemaElement> schema;
3: required i64 num_rows
4: required list<'a><RowGroup> row_groups
5: optional list<KeyValue> key_value_metadata
6: optional string<'a> created_by
7: optional list<ColumnOrder> column_orders;
8: optional EncryptionAlgorithm encryption_algorithm
9: optional binary<'a> footer_signing_key_metadata
}
);
这个系统使得Thrift定义和Rust结构之间的对应关系一目了然,并且很容易支持像GeospatialStatistics这样新添加的功能。对于最重要的性能关键结构,例如RowGroupMetaData和ColumnChunkMetaData,经过精心手动优化的解析器更新起来虽然更难,但仍然直接(参见#8587)。然而,这些结构也不太可能经常改变。
未来的改进
有了自定义解析器,我们正在努力进行额外的改进
- 实现特殊的“跳过”索引,以直接跳到特定查询所需的元数据部分,例如行组偏移量。
- 有选择地仅解码特定查询所需列的统计信息。
- 有可能将宏贡献回 thrift crate。
结论
我们认为许多开源 Parquet 读取器中的元数据解析速度缓慢,主要是因为它们使用了由 Thrift 编译器自动生成的解析器,这些解析器并未针对 Parquet 元数据解析进行优化。通过编写自定义解析器,我们显著加快了 parquet Rust crate 中的元数据解析,该 crate 在 Apache Arrow 生态系统中广泛使用。
虽然这不是第一个用于 Parquet 元数据的开源自定义 Thrift 解析器(CUDF 多年来一直拥有一个),但我们希望我们的结果能鼓励其他 Parquet 实现考虑类似的优化。本文描述的方法和优化可能适用于 C++ 和 Java 等其他语言的 Parquet 实现。
以前,像这样的努力只有资金充足的商业企业才能实现。我们代表 arrow-rs 和 Parquet 的贡献者,很高兴能在即将发布的 57.0.0 版本中与社区分享这项技术,并邀请您 加入我们,帮助它变得更好!