Arrow C++ 中哈希连接的近期改进
发布 2025 年 7 月 18 日
作者 Rossi Sun (zanmato)
编者按:Apache Arrow 是一个广阔的项目,涵盖了 Arrow 自身的列式格式、众多规范以及大量的实现。Arrow 也是一个在贡献者社区方面广阔的项目。在这篇博文中,我们想重点介绍 Apache Arrow Committer Rossi Sun 最近在提高 Arrow 可嵌入查询执行引擎 Acero 的性能和稳定性方面所做的工作。
简介
哈希连接是分析处理引擎中的一个基本操作——它使用哈希表进行快速查找,根据键值匹配两个表中的行。在 Apache Arrow 的 C++ 实现中,哈希连接是在 C++ 引擎 Acero 中实现的,该引擎为 PyArrow 和 R Arrow 包等绑定中的查询执行提供支持。即使您没有直接使用 Acero,您的代码也可能已经在底层受益于它。
例如,这个简单的 PyArrow 示例使用 Acero
import pyarrow as pa
t1 = pa.table({'id': [1, 2, 3],
'year': [2020, 2022, 2019]})
t2 = pa.table({'id': [3, 4],
'n_legs': [5, 100],
'animal': ["Brittle stars", "Centipede"]})
t1.join(t2, 'id').combine_chunks().sort_by('year')
Acero 最初创建于 2019 年,旨在证明 Arrow C++ 中不断增长的计算内核库可以组合成实际的工作流,并利用新兴的 Datasets API 为这些工作流提供数据访问。Acero 的目标不是与 DuckDB 等完整的查询引擎竞争,而是专注于实现灵活、可组合和可嵌入的查询执行——作为需要快速、模块化分析功能的工具和系统的构建块,包括那些基于 Arrow C++ 构建的,或通过 PyArrow、Substrait 或 ADBC 等绑定进行集成的系统。
在最近的几个 Arrow C++ 版本中,我们对哈希连接的实现进行了重大改进,以解决常见的用户痛点。这些更改提高了稳定性、内存效率和并行性能,重点是使连接更易于使用且开箱即用即可扩展。如果您过去在使用 Arrow 的哈希连接时遇到过问题,现在是再次尝试的好时机。
安全扩展:稳定性改进
在 Arrow C++ 的早期版本中,哈希连接实现使用了并非为超大数据集设计的内部数据结构,并且在某些底层内存操作中缺乏保护措施。这些限制在小型到中型工作负载中很少出现,但在规模化时变得有问题,表现为崩溃或细微的正确性问题。
Arrow 连接实现的核心是一个紧凑的行式结构,称为“行表”。虽然 Arrow 的数据模型是列式的,但其哈希连接实现以行式方式操作——类似于 DuckDB 和 Meta 的 Velox 等现代引擎。这种布局通过将键、有效载荷和空位在内存中并置,以便可以一起访问,从而最大限度地减少哈希表查找期间的 CPU 缓存未命中。
在以前的版本中,行表使用 32 位偏移量来引用打包的行。这使得每个表的大小上限为 4GB,并在处理大型数据集或宽行时引入了溢出的风险。几个报告的问题——GH-34474、GH-41813 和 GH-43202——凸显了这种设计的局限性。作为回应,PR GH-43389 将内部偏移类型扩展到 64 位,重构了行表基础设施的关键部分,以更安全、更具可扩展性地支持更大的数据大小。
除了偏移限制之外,Arrow C++ 的早期版本还在整个哈希连接实现中使用的缓冲区索引路径中包含了容易溢出的逻辑。许多内部计算都假定 32 位整数足以寻址内存——这在处理大型数据集或宽行时是一个脆弱的假设。这些问题不仅出现在传统的 C++ 索引代码中,也出现在 Arrow 的 SIMD 加速路径中——Arrow 包含了大量的 SIMD 特化,用于加速哈希表探测和行比较等操作。总之,这些假设导致了细微的溢出和不正确的行为,如 GH-44513、GH-45334 和 GH-45506 等问题中所述。
两个代表性示例
- C++ 中的行式缓冲区访问
上述行表将固定长度的数据存储在紧密打包的缓冲区中。访问特定行(以及其中可选的列)通常涉及指针算术
const uint8_t* row_ptr = row_ptr_base + row_length * row_id;
当 row_length 和 row_id 都是大的 32 位整数时,它们的乘积可能会溢出。
同样,访问空掩码涉及空位索引算术
int64_t bit_id = row_id * null_mask_num_bytes * 8 + pos_after_encoding;
中间乘法使用 32 位算术执行,即使最终结果存储在 64 位变量中,也可能溢出。
- 使用 32 位偏移量的 SIMD gather
一个重要的 SIMD 指令是 AVX2 intrinsic __m256i _mm256_i32gather_epi32(int const * base, __m256i vindex, const int scale);,它根据八个 32 位有符号偏移量并行执行八个 32 位整数的内存 gather。它在 Arrow 中广泛用于哈希表操作,例如,在哈希表探测期间并行获取 8 个组 ID(哈希表槽)
__m256i group_id = _mm256_i32gather_epi32(elements, pos, 1);
并并行加载 8 个相应的键值从右侧输入进行比较
__m256i right = _mm256_i32gather_epi32((const int*)right_base, offset_right, 1);
如果任何计算出的偏移量超过 2^31 - 1,它们将折回负范围,这可能导致无效的内存访问(即崩溃),或者更微妙地,从有效但不正确的位置获取数据——产生无声的错误结果(相信我,你不会想调试那个)。
为了降低这些风险,PR GH-45108、GH-45336 和 GH-45515 将关键算术提升为 64 位,并重构了 SIMD 逻辑以使用更安全的索引。缓冲区访问逻辑也被封装在更安全的抽象中,以避免重复的手动类型转换或未经检查的偏移量数学运算。这些示例并非 Arrow 独有——它们反映了构建数据密集型系统中的常见陷阱,其中对整数大小未经检查的假设可能会悄然损害正确性。
总之,这些更改使 Arrow 的哈希连接实现显着更健壮,并且更适合现代数据工作负载。这些基础不仅解决了已知问题,还降低了未来开发中出现类似错误的风险。
更精简的内存使用
在改进哈希连接实现中易溢出的部分时,我最终检查了大部分代码路径以寻找潜在的陷阱。在做这种工作时,人们会安静地坐下来,逐行审问——不仅要问中间值是否会溢出,还要问它是否根本需要存在。在这个过程中,我发现了一些与溢出无关但影响更大的东西。
在教科书般的哈希连接算法中,一旦右侧表(构建侧)完全累积,就会构建一个哈希表以支持探测左侧表(探测侧)以查找匹配项。为了并行化此构建步骤,Arrow C++ 的实现将构建侧划分为 N 个分区——通常与可用的 CPU 内核数匹配——并为每个分区并行构建一个单独的哈希表。然后将这些哈希表合并成一个最终的统一哈希表,用于探测阶段。
问题是什么?内存占用。分区哈希表的总大小大约等于最终哈希表的大小,但即使在合并之后,它们仍然保留在内存中。一旦最终哈希表构建完成,这些临时结构就没有进一步的用处了——但它们却在整个连接操作中持续存在。没有崩溃,没有警告,没有可见的危险信号——只是无声的开销。
一旦发现,修复很简单:重构连接过程,在合并后立即释放这些缓冲区。此更改在 PR GH-45552 中实现。下面的内存配置文件说明了其影响。
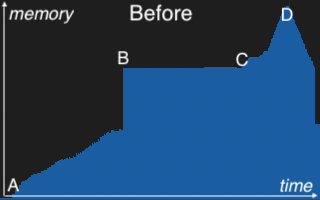
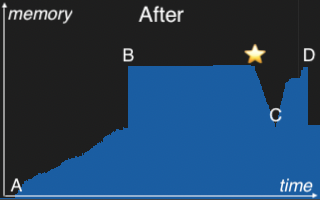
在 A 处,内存使用量随着连接并行构建分区哈希表而稳步上升。B 标记了合并点,这些分区在此处合并成一个最终的统一哈希表。C 表示探测阶段的开始,其中扫描左侧表并与最终哈希表进行匹配。随着连接结果的实例化,内存再次开始上升。D 是连接操作的峰值,就在处理完成内存开始下降之前。“飞跃”发生在右侧配置文件上的星号处,分区哈希表在合并后立即释放。这种早期释放释放了大量内存,并为下游处理腾出了空间——降低了在 D 处观察到的总峰值内存。
这项改进已经使实际场景受益——例如,DuckDB Labs DB Benchmark。一些以前因内存不足 (OOM) 错误而失败的基准查询现在可以成功完成——如下面的比较所示。
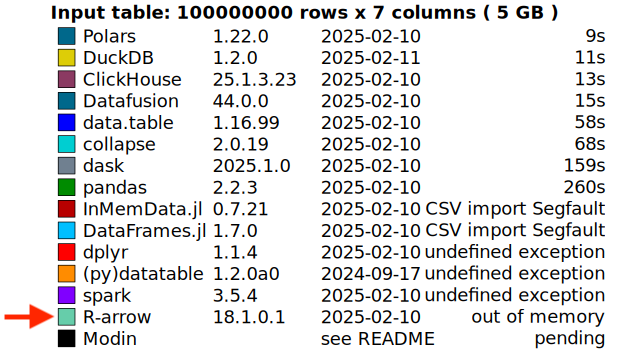
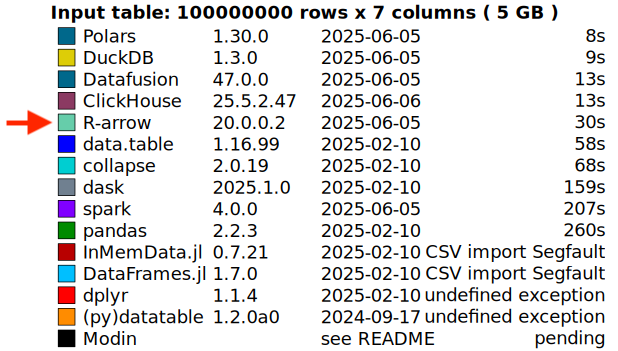
正如一位审阅者在 PR 中指出的那样,这是一个“唾手可得的果实”。有时,有意义的性能提升并非来自调整热循环或深入研究火焰图——它们来自注意到某些不正确的东西并提出问题:我们为什么还要保留这个?
通过更好的并行化实现更快的执行
并非所有改进都来自仔细研究火焰图——但有些确实如此。毕竟,性能是任何查询引擎最受关注的方面。那么,来一杯火焰图怎么样?
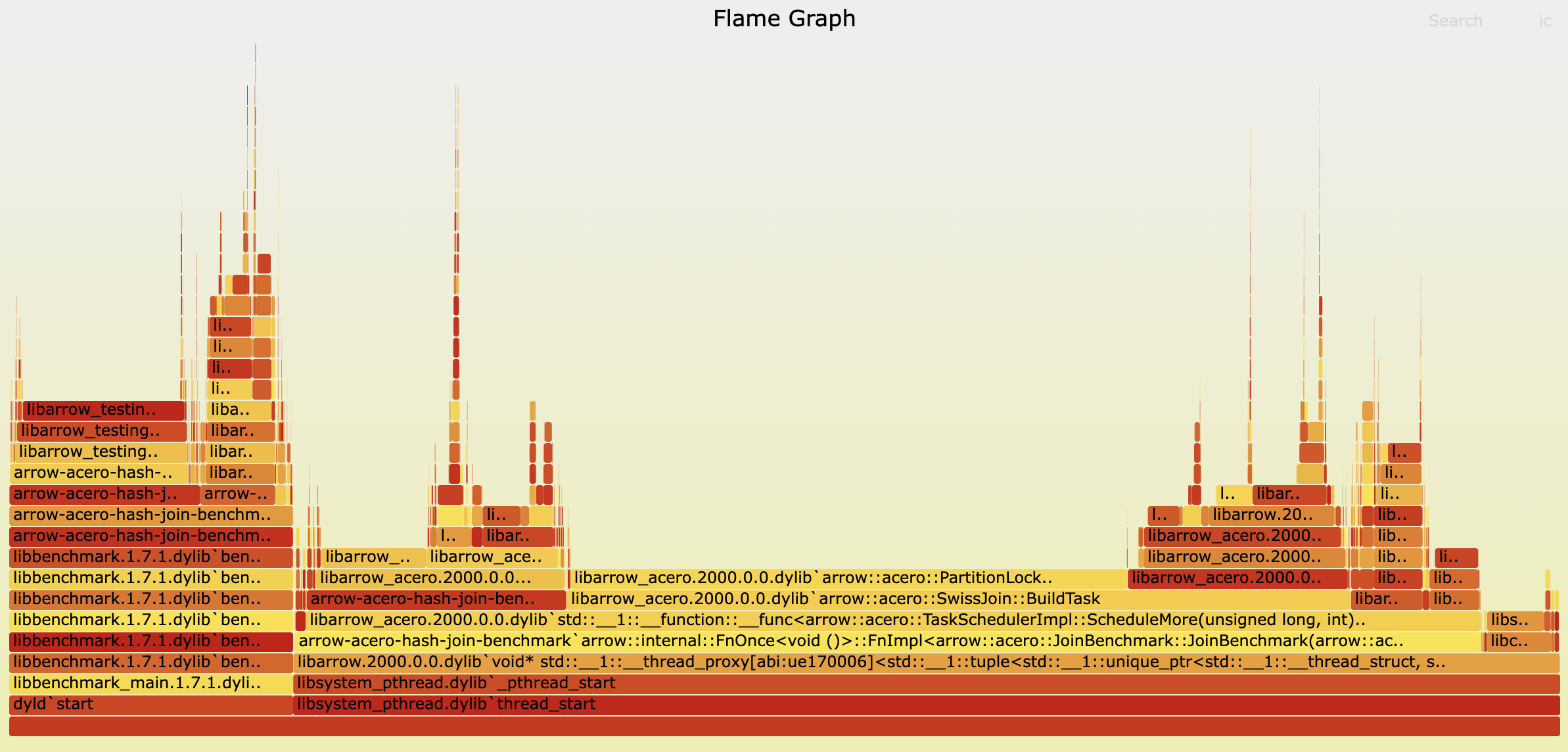
很难不注意到中间长而平坦的条形图占据主导地位——尤其是其中包含“Lock”这个相当令人担忧的词。那是我们的危险信号。
我们已经提到,在构建阶段,我们并行构建分区哈希表。在 Arrow C++ 的早期版本中,这种并行性是基于批处理实现的——每个线程并发处理一个构建侧批处理。由于每个批处理包含可能属于任何分区的任意数据,因此线程在访问共享分区时必须同步。这是通过分区上的锁来管理的。尽管我们引入了一些随机的锁定顺序以减少争用,但它仍然很高——在火焰图中清晰可见。
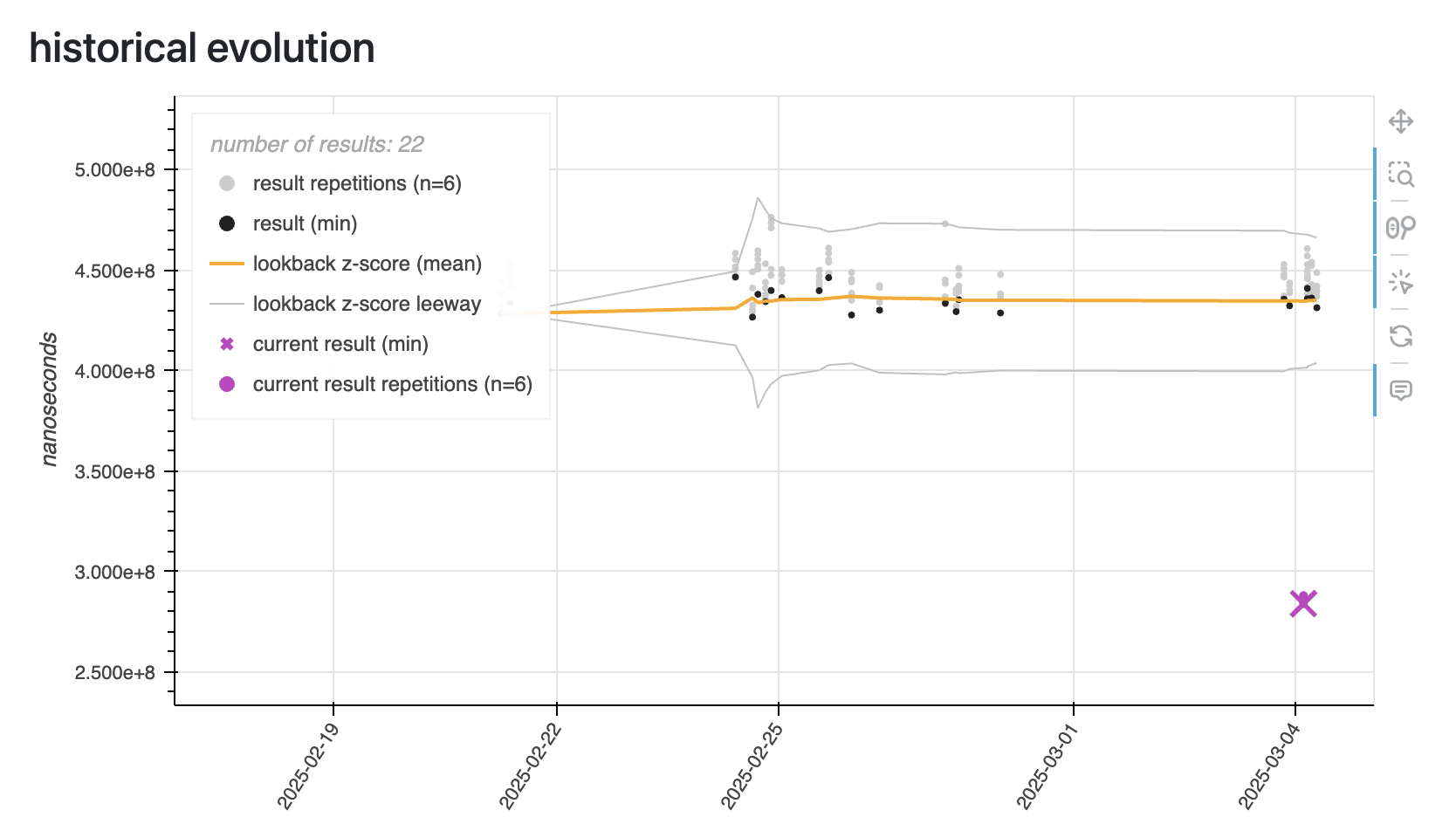
为了缓解这种争用,我们在 PR GH-45612 中重构了构建阶段。我们没有让所有线程同时分区和插入——每个线程都触及每个哈希表——而是将工作分为两个不同的阶段。在第一个分区阶段,M 个线程获取它们分配的批次并仅对其进行分区,记录哪些行属于哪个分区。此时还没有发生插入——只是分类。然后是第二个,新分离的构建阶段。在这里,N 个线程接管,每个线程负责构建一个 N 个分区哈希表中的一个。每个线程扫描所有批次中所有相关的分区,但只插入属于其分配分区的行。这种重构消除了插入期间线程之间锁定的需要——每个线程现在对其分区哈希表拥有独占访问权限。通过以这种方式解耦工作,我们将一个高度争用的操作变成了一个干净的、令人尴尬的并行操作。结果,我们在专用构建基准测试中看到性能提高了多达 10 倍。下面的示例来自一个更典型的通用工作负载——并不是特别构建密集型——但它仍然显示出扎实的 2 倍加速。在图表中,用紫色图标 🟣⬇️ 标记的飞跃代表应用了此改进的结果,而灰色和黑色的则显示了更改之前的早期运行。
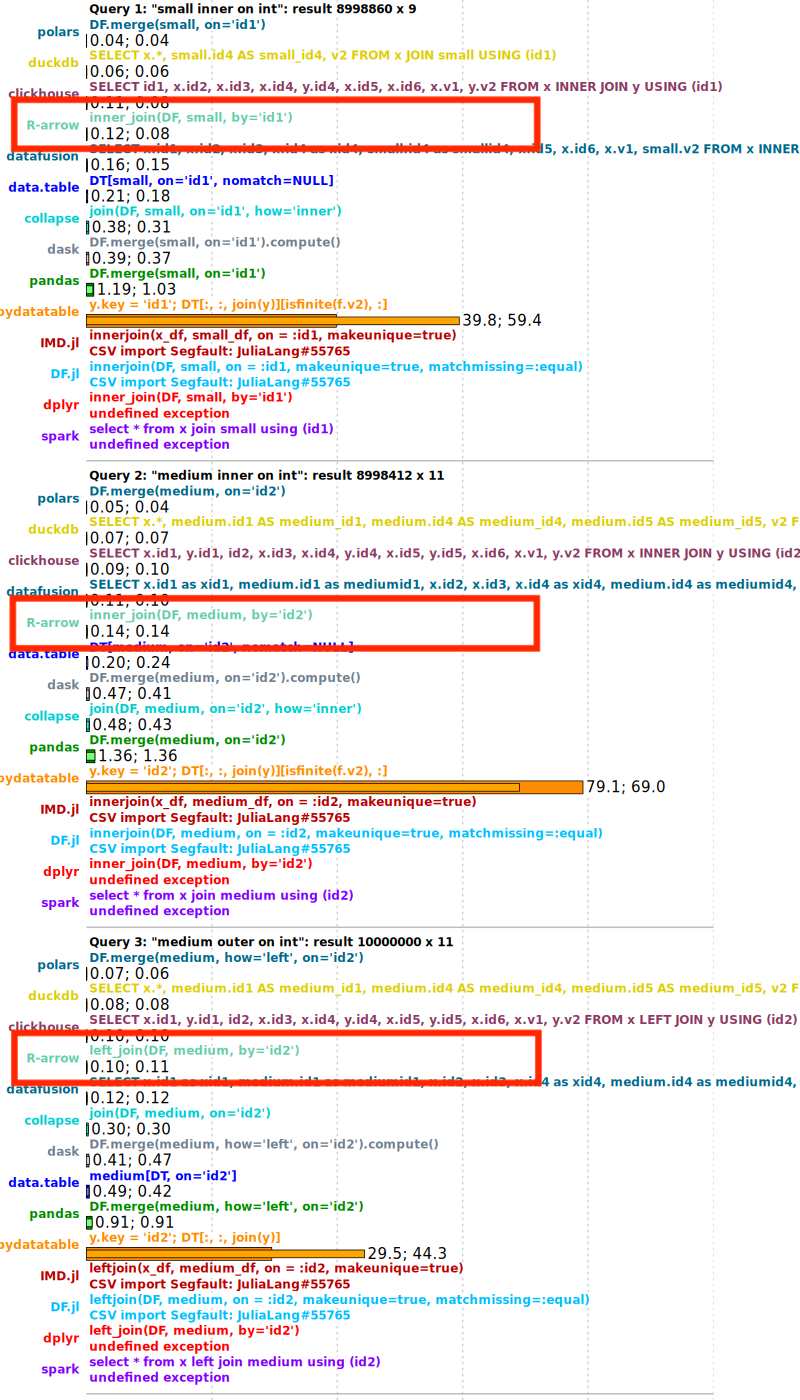
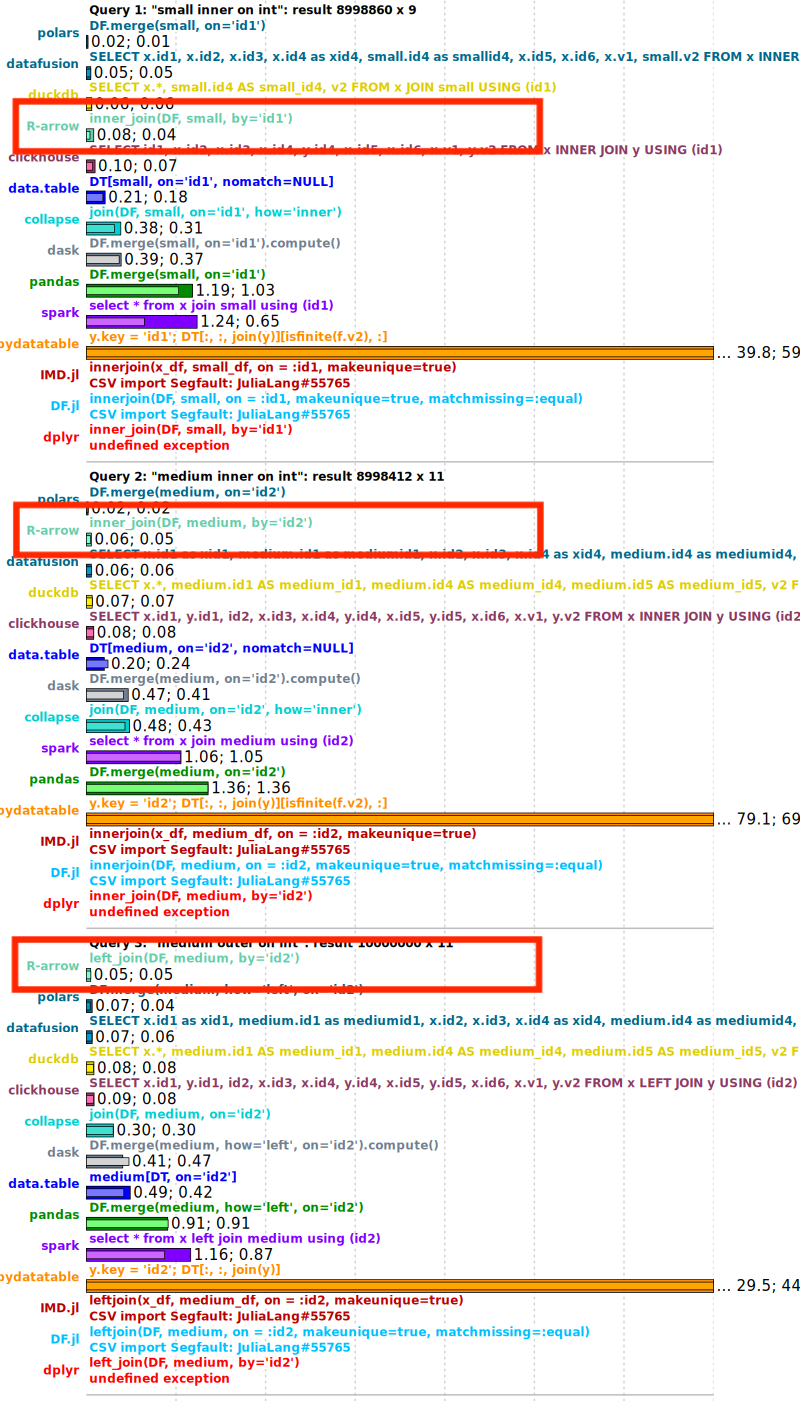
在像 DuckDB Labs DB Benchmark 这样的实际场景中,我们也观察到了类似的收益。下面的比较显示,在应用此更改后,查询性能大约提高了 2 倍。
其他改进包括 GH-43832,它将 AVX2 加速扩展到更多的探测代码路径,以及 GH-45918,它将并行性引入到以前的顺序任务阶段。这些针对更专业的场景和边缘情况。
总结
这些改进反映了对 Arrow C++ 执行引擎的持续投入,以及致力于为分析工作负载提供快速、强大的构建块的承诺。它们在最新的 Arrow C++ 版本中提供,并通过 PyArrow 和 Arrow R 包等高级绑定公开——从 18.0.0 版本开始,最显著的改进在 20.0.0 版本中。如果之前连接操作对您来说是一个障碍——由于内存、规模或正确性问题——那么最近的更改可能会带来截然不同的体验。
Arrow C++ 引擎不仅活跃,而且正在以有意义的、用户可见的方式改进。我们还在积极监控进一步的问题,并乐于根据用户反馈和实际需求扩展设计。如果您过去曾尝试过连接操作并遇到性能或稳定性问题,我们鼓励您再次尝试,如果遇到任何问题,请在 GitHub 上提交问题。
如果您对本博客文章有任何疑问,请随时联系作者 Rossi Sun。