使用 ADBC 在 DuckDB 中实现快速流式插入
发布 2025年3月10日
作者 Loïc Alleyne (loicalleyne)
 # TL;DR
# TL;DRDuckDB 正迅速成为数据从业者工具箱中不可或缺的一部分,在数据工程、机器学习和本地分析中找到了用武之地。在许多情况下,DuckDB 被用于查询和处理已由另一个进程保存到存储(基于文件或外部数据库)的数据。Arrow 数据库连接 API 能够使用 DuckDB 作为引擎进行高吞吐量数据处理。
事情的开端
我所在的公司是领先的数字户外营销平台,包括一个程序化广告技术栈。几年来,我的技术运营团队一直在使用实时程序化拍卖系统以 Apache Avro 格式发出的日志。随着时间的推移,我们使用这些数据构建了整个运营和分析后端。Avro 文件是基于行的,对于大规模分析来说并不理想,实际上是相当痛苦的。以至于我开发并贡献了一个 Avro 读取器功能到 Apache Arrow Go 库,以便能够将 Avro 文件转换为 Parquet。现在,这个数据管道正在平稳运行,每天将数百 GB 的数据从 Avro 转换为 Parquet。
由于“计算机科学中的任何问题都可以通过另一层间接来解决”,原始系统增加了层(像洋葱一样),并开始发出其他日志,这次是 Apache Parquet 格式...

- 新的洋葱层(咳咳...系统组件)将 Protobuf 编码的消息发送到 Kafka 主题
- 一个带有 S3 Sink 连接器的 Kafka Connect 集群消费主题并将 Parquet 文件保存到对象存储
由于数据的洪流,集群规模随着时间的推移增长到 > 25 个节点,并且每小时生成数千个小型 Parquet 文件(13 MB 或更小)。这导致查询延迟不断增加,在某些情况下由于查询超时(即小文件问题)而导致我们的工具崩溃。更不用说在我们的数据仓库中对原始数据运行聚合既不快也不便宜。
DuckDB 来救援... 我想
我曾使用 DuckDB 处理和分析 Parquet 数据,所以我知道它能很快完成。然后我在 LinkedIn 上看到了这篇文章(使用 Kafka 和 DuckDB 进行实时分析),有人使用 DuckDB 在 Go 中构建了一个近实时分析系统。
幻灯片列出了 DuckDB 的限制
发布者的解决方案在应用层批量处理数据,成功将摄取速度提高了 100 倍,达到约 2 万次插入/秒,并指出他们认为使用 DuckDB Appender API 可能会将此速度提高 10 倍。因此,潜在地达到约 20 万次插入/秒。太棒了...
 发布者的解决方案在应用层批量处理数据,成功将摄取速度提高了 100 倍,达到约 2 万次插入/秒,并指出他们认为使用 DuckDB Appender API 可能会将此速度提高 10 倍。因此,潜在地达到约 20 万次插入/秒。太棒了...
发布者的解决方案在应用层批量处理数据,成功将摄取速度提高了 100 倍,达到约 2 万次插入/秒,并指出他们认为使用 DuckDB Appender API 可能会将此速度提高 10 倍。因此,潜在地达到约 20 万次插入/秒。太棒了...
然后我注意到幻灯片中的数据模式是扁平的,只有 4 个字段(而 OpenRTB 模式具有深度嵌套的列表和结构);然后我查看了我们的监控仪表板,意识到在高峰期我们的系统每秒发出的事件超过 25 万个。[悲伤长号声响起]
我没有被吓倒(也不是特别喜欢设置/运行/维护 Spark 集群的想法),我怀疑 Apache Arrow 的列式内存表示仍然可以使 DuckDB 可行,因为它有一个 Arrow API;获取 Parquet 文件就像运行 COPY...TO (format parquet) 一样简单。
使用在 Github 问题中找到的模式,我使用 github.com/marcboeker/go-duckdb 编写了一个 POC,连接到数据库,检索一个 Arrow,创建一个 Arrow Reader,在 Reader 上注册一个视图,然后从视图运行 INSERT 语句。
这感觉有点像兔子自己从帽子里拉出来,但没关系,它在我的笔记本电脑上每秒处理大约 74k 到 110k 行。
为了确保这确实是正确的解决方案,我还尝试了 DuckDB 的 Appender API(在撰写本文时是快速插入的官方推荐),并在我的笔记本电脑上实现了约 63k 行/秒。还行,但是……没什么特别的。
新的希望
在 Gopher Slack 的一次讨论中,Matthew Topol,又名 zeroshade,建议使用 ADBC 及其更简单的 API。你问 Matt Topol 是谁?他就是那个**真正**写了关于 Apache Arrow 的书的人(使用 Apache Arrow 进行内存分析:加速数据分析以高效处理平面和分层数据结构第 2 版)。它是一本关于使用 Arrow 的优秀资源和指南。
顺便说一句,如果您更喜欢用首字母缩略词来记住这本书的名字,那就是**IMAAA:ADAFEPOFAHDS2E**。
但我跑题了。Matt 也是 Apache Arrow PMC 的成员,Apache Iceberg Go 实现的主要贡献者,总的来说是一个友善、乐于助人的人。

ADBC
ADBC 是
-
一组用于处理数据库和 Arrow 数据的不同语言(C/C++、Go 和 Java,更多正在开发中)的抽象 API。
例如,ADBC 中查询的结果集都以 Arrow 数据流的形式返回,而不是逐行返回。
-
一组在不同语言(C/C++、C#/.NET、Go、Java、Python 和 Ruby)中实现的 API,它们针对不同的数据库(例如 PostgreSQL、SQLite、DuckDB、任何支持 Flight SQL 的数据库)。
回到最初的设想,我创建了 Quacfka,一个使用 ADBC 构建的 Go 库,并将我的系统分为 3 个工作池,通过通道连接
- Kafka 客户端消费主题消息并将字节写入消息通道
- 处理例程使用 Bufarrow 库反序列化 Protobuf 数据并将其附加到 Arrow 数组,将 Arrow 记录写入记录通道
- DuckDB 插入器将 Arrow 记录绑定到 ADBC 语句并执行插入
我首先串联运行这些程序,以确定每个程序能运行多快
2025/01/23 23:39:27 kafka read start with 8 readers
2025/01/23 23:39:41 read 15728642 kafka records in 14.385530 secs @1093365.498477 messages/sec
2025/01/23 23:39:41 deserialize []byte to proto, convert to arrow records with 32 goroutines start
2025/01/23 23:40:04 deserialize to arrow done - 15728642 records in 22.283532 secs @ 705841.509812 messages/sec
2025/01/23 23:40:04 ADBC IngestCreateAppend start with 32 connections
2025/01/23 23:40:25 duck ADBC insert 15728642 records in 21.145649535 secs @ 743824.007783 rows/sec
决定了这种架构后,我开始并发运行工作线程,对系统进行检测,分析我的代码以识别性能问题,并调整设置以最大化吞吐量。在我看来,有足够的性能余量可以进行飞行中聚合。
一个问题:尽管 DuckDB 具有出色的轻量级压缩,但来自该来源的插入使得文件大小以每分钟约**8GB**的速度增加。暂停插入以导出 Parquet 文件并释放存储会使整体吞吐量降低到无法接受的水平。我决定根据文件大小阈值实现数据库文件的轮换。
由于 DuckDB 能够查询磁盘或对象存储中的 Hive 分区 Parquet,因此可以通过运行一个单独的查询服务器来解耦分析部分和数据摄取管道,该服务器指向 Parquet 文件最终存储的位置。
通过迭代,我创建了几个 API,试图使飞行中聚合的效率足够高,以保持整体吞吐量高于我的 25 万行/秒的目标。
前两个要么遇到了数据局部性问题,要么优化不足
- **CustomArrows**:对每个 Arrow Record 运行的函数,以创建要与原始 Record 一起插入的新 Record
- **DuckRunner**:在旋转之前对数据库文件运行一系列查询
推理表明,如果对 Arrow Record 数组中深度嵌套的数据进行解嵌套会导致数据局部性问题
- **Normalizer**:在反序列化函数中使用的 Bufarrow API,用于规范化消息数据并将其附加到另一个 Arrow Record 中,插入到单独的表中
这种方法使吞吐量回升到几乎与没有 Normalizer 时一样高的水平——扁平数据处理和插入速度快得多。
噢,我们已经成功了一半……靠着祈祷坚持着
接下来,我尝试打开与多个数据库的并发连接。**砰!**_**段错误**_。DuckDB 的并发模型并非如此设计。在一个进程中只能打开一个数据库(内存中或文件),然后其他数据库文件可以附加到中心数据库的目录中。
我已经决定轮换 DB 文件,因此我决定创建一个单独的程序 (Runner) 来处理轮换的数据库文件,对规范化数据进行聚合并将表转储到 parquet。这意味着需要在两者之间建立 RPC 连接并找出一种背压机制,以避免出现 `磁盘已满` 事件。
然而,同时运行这两个程序会导致内存压力问题,更不用说会大大降低吞吐量。将虚拟机升级到具有更多 vCPU 和内存的虚拟机只起到了一点帮助,显然存在一些资源争用。
自 Go 1.5 起,默认的 `GOMAXPROCS` 值是可用的 CPU 核心数。如果将其减少到“沙盒”摄取进程,并设置 Runner 中的 DuckDB 线程数呢?这实际上效果非常好,增加了整体吞吐量。Runner 运行 `COPY...TO...parquet` 查询,遍历 parquet 输出文件夹,将文件上传到对象存储并删除已上传的文件。平衡 Quafka-Service 中的 DuckDB 文件轮换大小阈值,使 Runner 能够跟上进度并避免磁盘上出现数据库文件积压。
结果
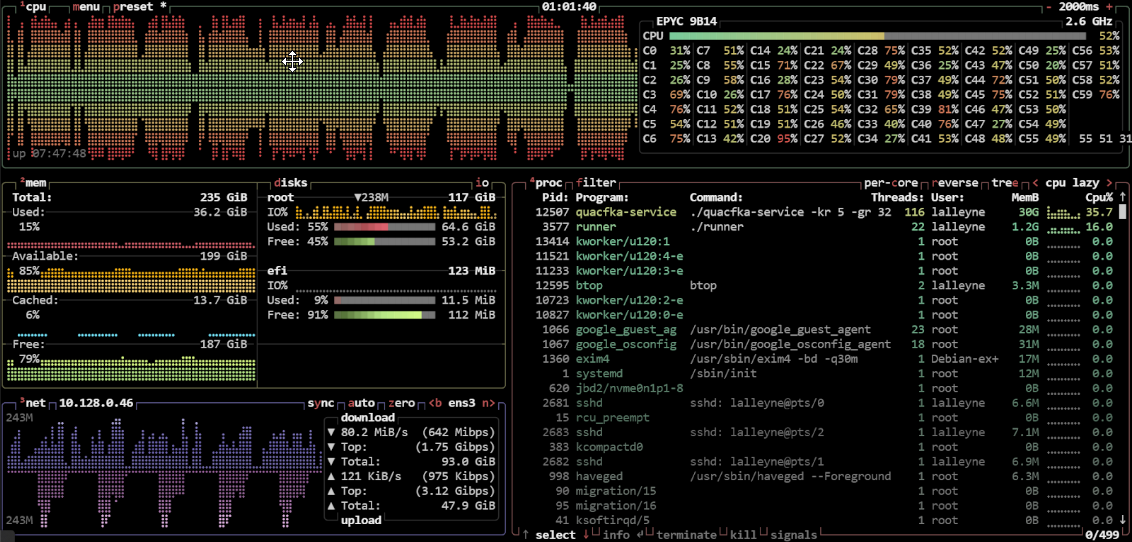
摄取原始数据(14 个字段,其中一个深度嵌套的 LIST.STRUCT.LIST 字段)+ 规范化数据
num_cpu: 60
runtime_os: linux
kafka_clients: 5
kafka_queue_cap: 983040
processor_routines: 32
arrow_queue_cap: 4
duckdb_threshold_mb: 4200
duckdb_connections: 24
normalizer_fields: 10
start_time: 2025-02-24T21:06:23Z
end_time: 2025-02-24T21:11:23Z
records: 123_686_901.00
norm_records: 122_212_452.00
data_transferred: 146.53 GB
duration: 4m59.585s
records_per_second: 398_271.90
total_rows_per_second: 806_210.41
transfer_rate: 500.86 MB/second
duckdb_files: 9
duckdb_files_MB: 38429
file_avg_duration: 33.579s如果只插入扁平的规范化数据,我们能得到多少行/秒? (注意:原始记录仍会处理,只是不插入)
num_cpu: 60
runtime_os: linux
kafka_clients: 10
kafka_queue_cap: 1228800
processor_routines: 32
arrow_queue_cap: 4
duckdb_threshold_mb: 4200
duckdb_connections: 24
normalizer_fields: 10
start_time: 2025-02-25T19:04:33Z
end_time: 2025-02-25T19:09:36Z
records: 231_852_772.00
norm_records: 363_247_327.00
data_transferred: 285.76 GB
duration: 5m3.059s
records_per_second: 0.00
total_rows_per_second: 1_198_601.39
transfer_rate: 965.54 MB/second
duckdb_files: 5
duckdb_files_MB: 20056
file_avg_duration: 58.975s
部署后,parquet 文件数量从每小时约 3000 个小文件降至每小时 < 20 个文件。再见小文件!

挑战/经验教训
- DuckDB 插入是瓶颈;网络速度、Protobuf 反序列化、**构建 Arrow Records 不是**。
- 为了最快地插入 DuckDB,Arrow Record Batches 应该包含至少 122880 行(以与 DuckDB 存储行组大小对齐)。
- DuckDB 不允许在同一进程中同时打开多个数据库(会导致段错误)。DuckDB 被设计为在一个进程中只运行一次,其中心数据库的目录能够添加与其他数据库的连接。
- 解决方法
- 使用单独的进程来写入和读取多个数据库文件。
- 打开一个 DuckDB 数据库并使用 ATTACH 连接其他数据库文件。
- 解决方法
- 扁平数据比嵌套数据插入速度快得多。

ADBC 为 DuckDB 提供了真正高吞吐量的数据摄取 API,为将 DuckDB 与流数据结合使用解锁了一系列用例,使其成为数据从业者越来越有用的工具。