数据渴望自由:使用 Apache Arrow 进行快速数据交换
发布 2025年2月28日
作者 David Li, Ian Cook, Matt Topol
这是系列文章中的第二篇,旨在揭开 Arrow 作为数据库和查询引擎数据交换格式的神秘面纱。
本系列文章
作为数据从业者,我们经常发现我们的数据“被挟持”。我们无法在获得数据后立即使用,而不得不花费时间——解析和清理效率低下、杂乱的 CSV 文件,等待过时的查询引擎处理几千兆字节的数据,以及等待数据通过套接字传输。今天我们将重点关注最后一点。在一个千兆网络时代,为什么这仍然是一个问题?毋庸置疑,这是一个问题——Mark Raasveldt 和 Hannes Mühleisen 在他们2017年的论文1中研究发现,一些系统传输一个只需要十秒的数据集却需要超过十分钟2。
我们为什么要等比所需时间长60倍?正如我们之前所论证的,序列化开销困扰着我们的工具——而 Arrow 可以帮助我们解决这个问题。所以让我们更具体地说明:我们将比较 PostgreSQL 和 Arrow 如何编码相同数据,以说明数据序列化格式的影响。然后我们将介绍使用 Arrow 构建协议的各种方式,例如 Arrow HTTP 和 Arrow Flight,以及您可能如何使用它们。
PostgreSQL 与 Arrow:数据序列化
让我们在相同的数据集上比较PostgreSQL 二进制格式和Arrow IPC,并展示 Arrow(凭借事后诸葛的优势)如何比其前身做出更好的权衡。
当您执行 PostgreSQL 查询时,客户端/驱动程序使用 PostgreSQL 线协议发送查询并获取结果。在该协议内部,结果集使用 PostgreSQL 二进制格式编码3。
首先,我们将创建一个表并填充数据
postgres=# CREATE TABLE demo (id BIGINT, val TEXT, val2 BIGINT);
CREATE TABLE
postgres=# INSERT INTO demo VALUES (1, 'foo', 64), (2, 'a longer string', 128), (3, 'yet another string', 10);
INSERT 0 3
然后我们可以使用 COPY 命令将原始二进制数据从 PostgreSQL 导出到一个文件
postgres=# COPY demo TO '/tmp/demo.bin' WITH BINARY;
COPY 3
然后我们可以根据文档标注数据的实际字节
00000000: 50 47 43 4f 50 59 0a ff PGCOPY.. COPY signature, flags,
00000008: 0d 0a 00 00 00 00 00 00 ........ and extension
00000010: 00 00 00 00 03 00 00 00 ........ Values in row
00000018: 08 00 00 00 00 00 00 00 ........ Length of value
00000020: 01 00 00 00 03 66 6f 6f .....foo Data
00000028: 00 00 00 08 00 00 00 00 ........
00000030: 00 00 00 40 00 03 00 00 ...@....
00000038: 00 08 00 00 00 00 00 00 ........
00000040: 00 02 00 00 00 0f 61 20 ......a
00000048: 6c 6f 6e 67 65 72 20 73 longer s
00000050: 74 72 69 6e 67 00 00 00 tring...
00000058: 08 00 00 00 00 00 00 00 ........
00000060: 80 00 03 00 00 00 08 00 ........
00000068: 00 00 00 00 00 00 03 00 ........
00000070: 00 00 12 79 65 74 20 61 ...yet a
00000078: 6e 6f 74 68 65 72 20 73 nother s
00000080: 74 72 69 6e 67 00 00 00 tring...
00000088: 08 00 00 00 00 00 00 00 ........
00000090: 0a ff ff ... End of stream老实说,PostgreSQL 的二进制格式一目了然,乍一看也很紧凑。它只是一系列长度前缀字段。但仔细观察就不那么理想了。PostgreSQL 的开销与行数和列数成正比
- 每行都有一个2字节前缀,用于表示该行中的值数量。但是数据是表格形式的——我们已经知道这些信息,而且它不会改变!
- 每行中的每个值都有一个4字节前缀,用于表示后续数据的长度,如果值为 NULL 则为-1。但我们知道数据类型,而且它们不会改变——此外,大多数类型的值都有一个固定且已知的长度!
- 所有值都是大端序。但是我们的大多数设备都是小端序,因此数据必须进行转换。
例如,一个由 int32 值组成的单列,每行将有 4 字节数据和 6 字节开销——60% 被“浪费了!”4 列数越多,这个比例会好一点(但行数越多则不会);在极限情况下,我们接近“仅仅”50% 的开销。然后每个值都必须进行转换(即使字节序交换是微不足道的)。值得称赞的是,PostgreSQL 的格式至少便宜且易于解析——其他格式则使用“变长整数”编码等技巧,这相当昂贵。
Arrow 表现如何?我们可以使用 ADBC 将 PostgreSQL 表拉取到 Arrow 表中,然后像之前一样进行注释
>>> import adbc_driver_postgresql.dbapi
>>> import pyarrow.ipc
>>> conn = adbc_driver_postgresql.dbapi.connect("...")
>>> cur = conn.cursor()
>>> cur.execute("SELECT * FROM demo")
>>> data = cur.fetchallarrow()
>>> writer = pyarrow.ipc.new_stream("demo.arrows", data.schema)
>>> writer.write_table(data)
>>> writer.close()
00000000: ff ff ff ff d8 00 00 00 ........ IPC message length
00000008: 10 00 00 00 00 00 0a 00 ........ IPC schema
⋮ (208 bytes)
000000e0: ff ff ff ff f8 00 00 00 ........ IPC message length
000000e8: 14 00 00 00 00 00 00 00 ........ IPC record batch
⋮ (240 bytes)
000001e0: 01 00 00 00 00 00 00 00 ........ Data for column #1
000001e8: 02 00 00 00 00 00 00 00 ........
000001f0: 03 00 00 00 00 00 00 00 ........
000001f8: 00 00 00 00 03 00 00 00 ........ String offsets
00000200: 12 00 00 00 24 00 00 00 ....$...
00000208: 66 6f 6f 61 20 6c 6f 6e fooa lon Data for column #2
00000210: 67 65 72 20 73 74 72 69 ger stri
00000218: 6e 67 79 65 74 20 61 6e ngyet an
00000220: 6f 74 68 65 72 20 73 74 other st
00000228: 72 69 6e 67 00 00 00 00 ring.... Alignment padding
00000230: 40 00 00 00 00 00 00 00 @....... Data for column #3
00000238: 80 00 00 00 00 00 00 00 ........
00000240: 0a 00 00 00 00 00 00 00 ........
00000248: ff ff ff ff 00 00 00 00 ........ IPC end-of-stream乍一看,Arrow 看起来相当……令人生畏。有一个巨大的头部,似乎与我们的数据集完全不相关,加上神秘的填充,似乎只是为了占用空间。但重要的是,开销是固定的。无论您传输一行还是一亿行,开销都不会改变。而且与 PostgreSQL 不同,不需要进行按值解析。
Arrow 不是在所有地方都放置值的长度,而是将相同列(因此类型相同)的值组合在一起,所以只需要缓冲区长度5。在不需要的地方不会增加开销。字符串仍然每个值都有一个长度。可空性则存储在位图中,如果没有任何 NULL 值则省略(就像这里一样)。因此,更多行数据并不会增加开销;相反,数据越多,您支付的开销就越少。
甚至那个头部也并非表面上看起来的劣势。头部包含模式,这使得数据流是自描述的。而使用 PostgreSQL,您需要从其他地方获取模式。所以我们一开始就没有进行完全对等的比较:PostgreSQL 仍然需要传输模式,只是它不属于我们这里查看的“二进制格式”6。
PostgreSQL 还有一个问题:对齐。每行开头的 2 字节字段计数意味着其后的所有 8 字节整数都未对齐。这需要额外的努力才能正确处理(例如,显式未对齐加载习惯用法),否则可能会导致未定义行为、性能损失,甚至运行时错误。另一方面,Arrow 有策略地添加了一些填充以保持数据对齐,并允许您根据数据使用小端或大端字节序。而且 Arrow 不会对数据应用需要进一步解析的昂贵编码。因此,通常情况下,您可以直接使用 Arrow 数据,而无需解析每个值。
这就是 Arrow 作为标准化数据格式的优势。通过使用 Arrow 进行序列化,从网络上传输的数据已经采用 Arrow 格式,并且可以进一步直接传递给 DuckDB、pandas、polars、cuDF、DataFusion 或任何其他系统。同时,即使 PostgreSQL 格式解决了这些问题——添加填充以对齐字段、使用小端或使字节序可配置、削减开销——您仍然需要将数据转换为另一种格式(可能是 Arrow)才能用于下游。
即使你真的想在所有地方都使用 PostgreSQL 二进制格式7,文档却不幸地将你指向 C 源代码作为文档。而 Arrow,则拥有规范、文档,以及跨十几种语言的多个实现(包括第三方),供你在自己的应用程序中选取使用。
我们并非有意在此挑剔 PostgreSQL。显然,PostgreSQL 是一个功能完备的数据库,历史悠久,拥有与 Arrow 不同的目标和限制,并且用户众多。Arrow 并不试图在该领域竞争。但它们的领域确实有交集。PostgreSQL 的线协议已成为事实上的标准,甚至像 Google 的 AlloyDB 这样的全新产品也使用它,因此其设计影响了许多项目8。事实上,AlloyDB 是一个很好的例子,一个崭新的列式查询引擎却被困在 90 年代面向行的客户端协议后面。所以阿姆达尔定律再次浮现——当数据管道的中间部分阻碍你时,优化“前端”和“后端”就无关紧要了。
Arrow 的“箭袋”(项目)
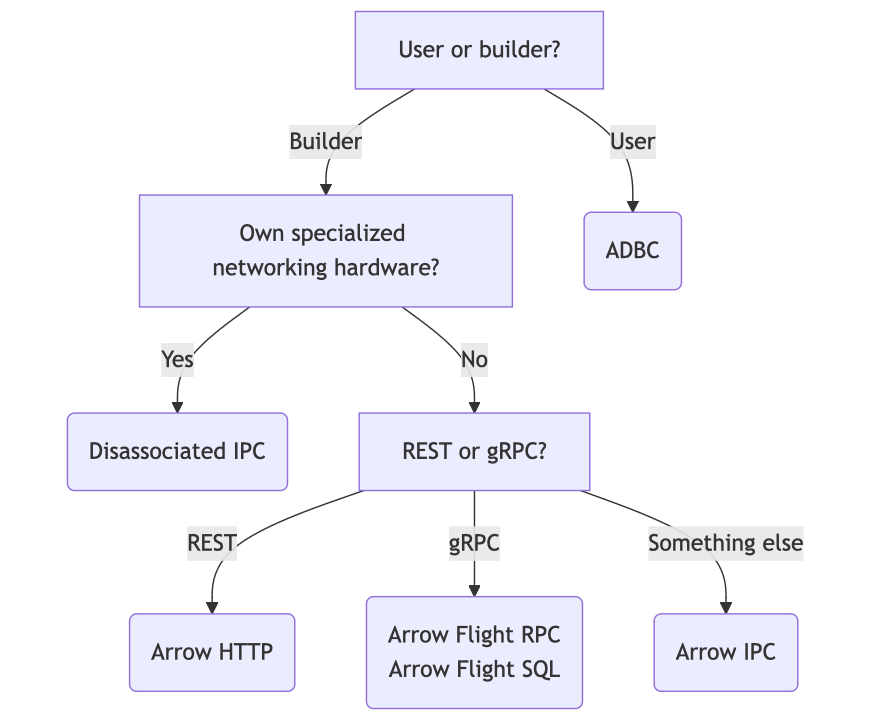
那么,如果 Arrow 这么出色,我们该如何实际使用它来构建我们自己的协议呢?幸运的是,Arrow 为不同情况提供了各种构建块。
- 我们刚才讨论了Arrow IPC。Arrow 是定义数据数组如何在内存中布局的内存格式,而 Arrow IPC 则定义了如何序列化和反序列化 Arrow 数据,以便将其发送到其他地方——无论是写入文件、写入套接字、写入共享缓冲区,还是其他方式。Arrow IPC 将数据组织成一系列消息,使其易于通过您喜欢的传输方式(如 WebSockets)进行流式传输。
- Arrow HTTP 仅仅是将 Arrow IPC 通过 HTTP 进行流式传输。Arrow 社区正在努力对其进行标准化,以便不同的客户端就如何精确地实现这一点达成一致。有多种语言的客户端和服务器示例,如何使用 HTTP Range 请求,使用 multipart/mixed 请求发送 JSON 和 Arrow 组合响应等等。虽然它本身不是一个完整的协议,但它在构建 REST API 时会非常适合。
- 解耦 IPC (Disassociated IPC) 将 Arrow IPC 与高级网络传输(如 UCX 和 libfabric)结合起来。对于那些需要绝对最佳性能并拥有专用硬件的用户,这使您能够以全速发送 Arrow 数据,利用 scatter-gather、Infiniband 等技术。
- Arrow Flight SQL 是一个用于访问关系型数据库的完整协议。可以将其视为完整 PostgreSQL 线协议的替代方案:它定义了如何连接到数据库、执行查询、获取结果、查看目录等等。对于数据库开发者来说,Flight SQL 提供了一个完全 Arrow 原生协议,并支持多种编程语言的客户端以及 ADBC、JDBC 和 ODBC 驱动程序——所有这些您都不必自己构建。
- 最后,ADBC 实际上不是一个协议。相反,它是一个用于处理数据库的 API 抽象层(就像 JDBC 和 ODBC——你没想到吧),它是 Arrow 原生的,不需要来回转换列式数据。ADBC 为您提供了一个单一的 API 来访问来自多个数据库的数据,无论它们底层使用 Flight SQL 还是其他什么,如果绝对需要转换,ADBC 会处理这些细节,这样您就不必自己构建十几个连接器了。
总结如下
- 如果您正在使用数据库或其他数据系统,您需要 ADBC。
- 如果您正在构建数据库,您需要 Arrow Flight SQL。
- 如果您正在使用专用网络硬件(您会知道您是否是——那些东西不便宜),您需要解耦 IPC 协议 (Disassociated IPC Protocol)。
- 如果您正在设计 REST-ish API,您需要 Arrow HTTP。
- 否则,您可以使用 Arrow IPC 自行构建。
 {:class="img-responsive" width="100%"}
{:class="img-responsive" width="100%"}
结论
现有的客户端协议可能效率低下。Arrow 提供了更高的效率,并避免了过去的设计缺陷。Arrow 通过 Arrow IPC、Arrow HTTP 和 ADBC 等各种标准,使构建和使用数据 API 变得容易。通过在协议中使用 Arrow 序列化,每个人都能从更轻松、更快速、更简单的数据访问中受益,我们可以避免将数据意外地限制在缓慢低效的接口后面。