在 Apache Arrow DataFusion 28.0.0 中快速聚合数百万个组
发布于 2023 年 8 月 5 日
作者 alamb, Dandandan, tustvold
在 Apache Arrow DataFusion 中快速聚合数百万个组
Andrew Lamb, Daniël Heres, Raphael Taylor-Davies,
注:本文最初发布于 InfluxData 博客
TLDR
分组聚合是任何分析工具的核心部分,可对海量数据进行易于理解的汇总。Apache Arrow DataFusion 在 新发布的 28.0.0 版本 中,对于包含大量(10,000 或更多)组的查询,其并行聚合能力提升了 2-3 倍。
改进聚合性能对所有 DataFusion 用户都至关重要。例如,时间序列数据平台 InfluxDB 和全栈可观测性平台 Coralogix 都聚合了大量原始数据,以监控并为我们的客户创建洞察。提高 DataFusion 的性能使我们能够通过更快地生成洞察并使用更少的资源来提供更好的用户体验。由于 DataFusion 是开源的,并在宽松的 Apache 2.0 许可下发布,因此整个 DataFusion 社区也从中受益。
通过新的优化,DataFusion 的分组速度现在接近 DuckDB,后者是一个经常报告 出色 分组 基准测试性能的系统。图 1 包含了 ClickBench 在单个 Parquet 文件上的代表性样本,完整结果位于本文末尾。
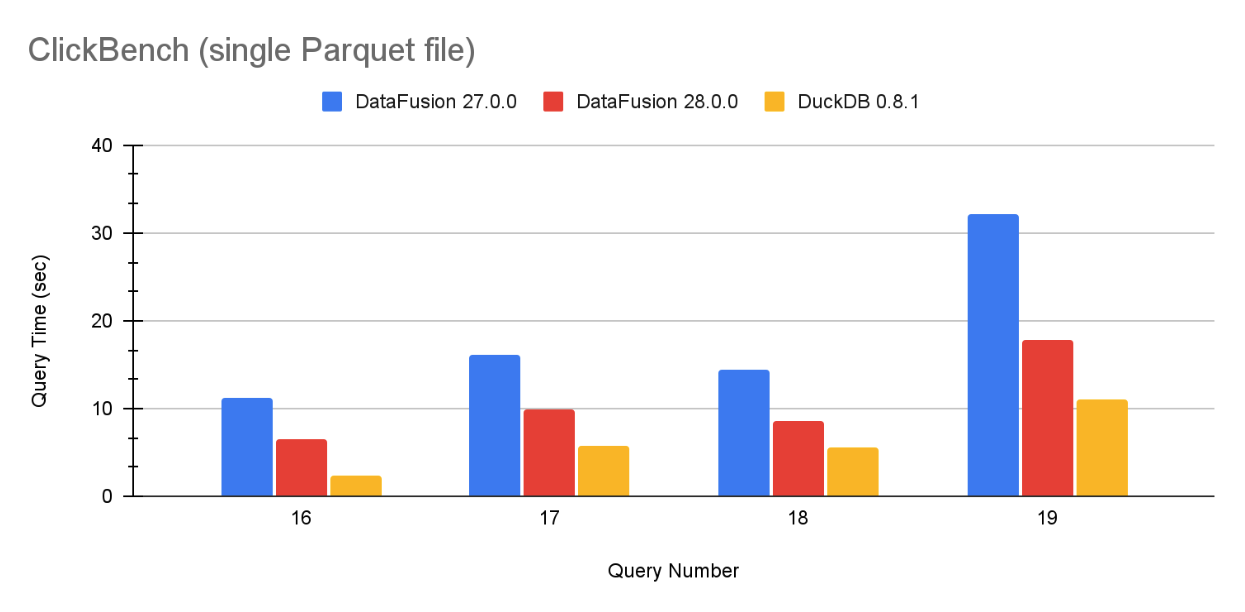
图 1:DataFusion 27.0.0、DataFusion 28.0.0 和 DuckDB 0.8.1 在单个 Parquet 文件上针对 ClickBench 查询 16、17、18 和 19 的查询性能。
高基数分组介绍
聚合是一个花哨的词,指计算多行数据的汇总统计信息,这些行在一个或多个列中具有相同的值。我们将具有相同值的行称为组,“高基数”表示数据集中有大量不同的组。在撰写本文时,分析引擎中“大量”的组大约为 10,000 个。
例如,ClickBench 的 hits 数据集包含 1 亿次匿名用户在网站上点击的数据。ClickBench 查询 17 是
SELECT "UserID", "SearchPhrase", COUNT(*)
FROM hits
GROUP BY "UserID", "SearchPhrase"
ORDER BY COUNT(*)
DESC LIMIT 10;
用英文来说,这个查询会找出“所有点击中排名前十的(用户,搜索词)组合”,并生成以下结果(排名前十的用户没有搜索词)
+---------------------+--------------+-----------------+
| UserID | SearchPhrase | COUNT(UInt8(1)) |
+---------------------+--------------+-----------------+
| 1313338681122956954 | | 29097 |
| 1907779576417363396 | | 25333 |
| 2305303682471783379 | | 10597 |
| 7982623143712728547 | | 6669 |
| 7280399273658728997 | | 6408 |
| 1090981537032625727 | | 6196 |
| 5730251990344211405 | | 6019 |
| 6018350421959114808 | | 5990 |
| 835157184735512989 | | 5209 |
| 770542365400669095 | | 4906 |
+---------------------+--------------+-----------------+
ClickBench 数据集包含
- 总行数 99,997,497 1
- 17,630,976 个不同的用户(不同的 UserIDs)2
- 6,019,103 个不同的搜索短语3
- 24,070,560 个不同的 (UserID, SearchPhrase) 组合4。因此,为了回答该查询,DataFusion 必须将 1 亿个不同的输入行中的每一个映射到 2400 万个不同的组中的一个,并统计每个组中有多少这样的行。
解决方案
像数据库和其他分析系统中的大多数概念一样,此算法的基本思想很简单,并在计算机科学入门课程中教授。您可以使用这样的程序计算查询5
import pandas as pd
from collections import defaultdict
from operator import itemgetter
# read file
hits = pd.read_parquet('hits.parquet', engine='pyarrow')
# build groups
counts = defaultdict(int)
for index, row in hits.iterrows():
group = (row['UserID'], row['SearchPhrase']);
# update the dict entry for the corresponding key
counts[group] += 1
# Print the top 10 values
print (dict(sorted(counts.items(), key=itemgetter(1), reverse=True)[:10]))
这种方法虽然简单,但既慢又内存效率低下。它需要超过 40 秒才能计算出不到 1% 的数据集的结果6。DataFusion 28.0.0 和 DuckDB 0.8.1 都在 10 秒内计算出整个数据集的结果。
要快速高效地回答此查询,您必须编写代码以使其
- 通过并行计算使所有核心保持忙碌状态
- 快速更新聚合值,使用易于编译器转换为现代 CPU 中可用的高性能 SIMD 指令的可矢量化循环。
本文的其余部分将解释 DataFusion 中的分组工作原理以及我们在 28.0.0 中所做的改进。
两阶段并行分区分组
DataFusion 27.0.0 和 28.0.0 都使用最先进的两阶段并行哈希分区分组,类似于其他高性能矢量化引擎,如 DuckDB 的并行分组聚合。从图片上看,这看起来像
▲ ▲
│ │
│ │
│ │
┌───────────────────────┐ ┌───────────────────┐
│ GroupBy │ │ GroupBy │ Step 4
│ (Final) │ │ (Final) │
└───────────────────────┘ └───────────────────┘
▲ ▲
│ │
└────────────┬───────────┘
│
│
┌─────────────────────────┐
│ Repartition │ Step 3
│ HASH(x) │
└─────────────────────────┘
▲
│
┌────────────┴──────────┐
│ │
│ │
┌────────────────────┐ ┌─────────────────────┐
│ GroupyBy │ │ GroupBy │ Step 2
│ (Partial) │ │ (Partial) │
└────────────────────┘ └─────────────────────┘
▲ ▲
┌──┘ └─┐
│ │
.─────────. .─────────.
,─' '─. ,─' '─.
; Input : ; Input : Step 1
: Stream 1 ; : Stream 2 ;
╲ ╱ ╲ ╱
'─. ,─' '─. ,─'
`───────' `───────'
图 2:两阶段重新分区分组:数据分两阶段从底部(源)流向顶部(结果)。首先(步骤 1 和 2),每个核心将数据读入核心特定的哈希表,计算中间聚合,无需任何跨核心协调。然后(步骤 3 和 4),DataFusion 按组值将数据分成不同的子集(“重新分区”),每个子集发送到一个特定的核心,该核心计算最终聚合。
这两个阶段对于在多核系统中保持核心忙碌至关重要。这两个阶段都使用相同的哈希表方法(在下一节中解释),但不同之处在于组的分布方式以及累加器发出的部分结果。第一阶段在数据生成后尽快聚合数据。然而,如图 2 所示,这些组可以存在于任何输入中的任何位置,因此相同的组通常在许多不同的核心上找到。第二阶段使用哈希函数将数据均匀地重新分布到各个核心上,因此每个组值都由一个核心精确处理,该核心会发出该组的最终结果。
┌─────┐ ┌─────┐
│ 1 │ │ 3 │
│ 2 │ │ 4 │ 2. After Repartitioning: each
└─────┘ └─────┘ group key appears in exactly
┌─────┐ ┌─────┐ one partition
│ 1 │ │ 3 │
│ 2 │ │ 4 │
└─────┘ └─────┘
─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
┌─────┐ ┌─────┐
│ 2 │ │ 2 │
│ 1 │ │ 2 │
│ 3 │ │ 3 │
│ 4 │ │ 1 │
└─────┘ └─────┘ 1. Input Stream: groups
... ... values are spread
┌─────┐ ┌─────┐ arbitrarily over each input
│ 1 │ │ 4 │
│ 4 │ │ 3 │
│ 1 │ │ 1 │
│ 4 │ │ 3 │
│ 3 │ │ 2 │
│ 2 │ │ 2 │
│ 2 │ └─────┘
└─────┘
Core A Core B
图 3:聚合阶段中,组值在 2 个核心上的分布。在第一阶段,每个核心处理的输入流中都存在每个组值 1、2、3、4。在第二阶段,重新分区后,组值 1 和 2 由核心 A 处理,而值 3 和 4 仅由核心 B 处理。
由于篇幅限制,DataFusion 实现 中还有一些未提及的额外细节,例如:
- 何时从第一阶段的哈希表中发出数据的策略(例如,因为数据部分已排序)
- 处理每个聚合的特定过滤器(由于
FILTERSQL 子句) - 中间值的数据类型(对于某些聚合,如
AVG,可能与最终输出不同)。 - 内存使用超出预算时采取的行动。
哈希分组
DataFusion 查询可以为每个组计算许多不同的聚合函数,包括 内置 和/或用户定义的 AggregateUDFs。每个聚合函数的状态,称为累加器,通过哈希表(DataFusion 使用出色的 HashBrown RawTable API)进行跟踪,该哈希表逻辑上存储标识特定组值的“索引”。
27.0.0 中的哈希分组
如图 3 所示,DataFusion 27.0.0 将数据存储在 GroupState 结构中,该结构毫无疑问地跟踪每个组的状态。每个组的状态包括
- 组列的实际值,采用 Arrow Row 格式。
- 每个组的进行中的累加(例如
COUNT聚合的运行计数),采用两种可能格式之一(Accumulator或RowAccumulator)。 - 用于跟踪每个批次中哪些行与每个聚合匹配的临时空间。
┌──────────────────────────────────────┐
│ │
│ ... │
│ ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ │
│ ┃ ┃ │
┌─────────┐ │ ┃ ┌──────────────────────────────┐ ┃ │
│ │ │ ┃ │group values: OwnedRow │ ┃ │
│ ┌─────┐ │ │ ┃ └──────────────────────────────┘ ┃ │
│ │ 5 │ │ │ ┃ ┌──────────────────────────────┐ ┃ │
│ ├─────┤ │ │ ┃ │Row accumulator: │ ┃ │
│ │ 9 │─┼────┐ │ ┃ │Vec<u8> │ ┃ │
│ ├─────┤ │ │ │ ┃ └──────────────────────────────┘ ┃ │
│ │ ... │ │ │ │ ┃ ┌──────────────────────┐ ┃ │
│ ├─────┤ │ │ │ ┃ │┌──────────────┐ │ ┃ │
│ │ 1 │ │ │ │ ┃ ││Accumulator 1 │ │ ┃ │
│ ├─────┤ │ │ │ ┃ │└──────────────┘ │ ┃ │
│ │ ... │ │ │ │ ┃ │┌──────────────┐ │ ┃ │
│ └─────┘ │ │ │ ┃ ││Accumulator 2 │ │ ┃ │
│ │ │ │ ┃ │└──────────────┘ │ ┃ │
└─────────┘ │ │ ┃ │ Box<dyn Accumulator> │ ┃ │
Hash Table │ │ ┃ └──────────────────────┘ ┃ │
│ │ ┃ ┌─────────────────────────┐ ┃ │
│ │ ┃ │scratch indices: Vec<u32>│ ┃ │
│ │ ┃ └─────────────────────────┘ ┃ │
│ │ ┃ GroupState ┃ │
└─────▶ │ ┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛ │
│ │
Hash table tracks an │ ... │
index into group_states │ │
└──────────────────────────────────────┘
group_states: Vec<GroupState>
There is one GroupState PER GROUP
图 4:DataFusion 27.0.0 中的哈希组运算符结构。哈希表将每个组映射到一个 GroupState,其中包含所有按组状态。
为了计算聚合,DataFusion 为每个输入批次执行以下步骤
- 使用 高效的矢量化代码 计算哈希,该代码针对每种数据类型进行了专门化。
- 使用哈希表确定每个输入行的组索引(为新发现的组创建新条目)。
- 更新每个具有输入行的组的累加器,如果有足够数量的行,则将这些行组装成连续范围,以用于矢量化累加器。
DataFusion 还将哈希值存储在表中,以避免在调整哈希表大小时可能耗时的哈希重新计算。
这种方案对于相对少量不同的组非常有效:所有累加器都使用大块连续的行有效地更新。
然而,这种方案对于高基数分组并不理想,原因在于
-
每个组多次分配内存,用于组值行格式,以及
RowAccumulator和每个Accumulator。Accumulator内部也可能进行额外的内存分配。 - 非矢量化更新: 由于每个输入批次中不同组的数量很大(因此每个组的值数量很小),累加器更新通常会退化为较慢的非矢量化形式。
28.0.0 中的哈希分组
对于 28.0.0,我们按照传统的系统优化原则重写了核心分组实现:更少的分配、类型专用化和激进的矢量化。
DataFusion 28.0.0 使用相同的 RawTable 并仍然存储组索引。如图 4 所示,主要区别在于
- 组值存储方式有两种:
- 直接内联在 `RawTable` 中(适用于原始类型的单列),此时转换为 Row 格式的开销大于其收益。
- 在一个单独的 Rows 结构中,所有组值都在一个连续的分配中,而不是每个组一个分配。累加器在内部管理所有组的状态,因此更新中间值的代码是一个紧密的类型专用循环。新的
GroupsAccumulator接口带来了高效的类型累加器更新循环。
┌───────────────────────────────────┐ ┌───────────────────────┐
│ ┌ ─ ─ ─ ─ ─ ┐ ┌─────────────────┐│ │ ┏━━━━━━━━━━━━━━━━━━━┓ │
│ │ ││ │ ┃ ┌──────────────┐ ┃ │
│ │ │ │ ┌ ─ ─ ┐┌─────┐ ││ │ ┃ │┌───────────┐ │ ┃ │
│ │ X │ 5 │ ││ │ ┃ ││ value1 │ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ │└───────────┘ │ ┃ │
│ │ Q │ 9 │──┼┼──┐ │ ┃ │ ... │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ └──┼─╋─▶│ │ ┃ │
│ │ ... │ ... │ ││ │ ┃ │┌───────────┐ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ ││ valueN │ │ ┃ │
│ │ H │ 1 │ ││ │ ┃ │└───────────┘ │ ┃ │
│ │ │ │ ├ ─ ─ ┤├─────┤ ││ │ ┃ │values: Vec<T>│ ┃ │
│ Rows │ ... │ ... │ ││ │ ┃ └──────────────┘ ┃ │
│ │ │ │ └ ─ ─ ┘└─────┘ ││ │ ┃ ┃ │
│ ─ ─ ─ ─ ─ ─ │ ││ │ ┃ GroupsAccumulator ┃ │
│ └─────────────────┘│ │ ┗━━━━━━━━━━━━━━━━━━━┛ │
│ Hash Table │ │ │
│ │ │ ... │
└───────────────────────────────────┘ └───────────────────────┘
GroupState Accumulators
Hash table value stores group_indexes One GroupsAccumulator
and group values. per aggregate. Each
stores the state for
Group values are stored either inline *ALL* groups, typically
in the hash table or in a single using a native Vec<T>
allocation using the arrow Row format
图 5:DataFusion 28.0.0 中的哈希组运算符结构。组值直接存储在哈希表中,或者使用 Arrow Row 格式的单个分配中。哈希表包含组索引。单个 GroupsAccumulator 存储所有组的每个聚合状态。
这种新结构显著提高了高基数组的性能,原因如下:
- 减少内存分配:不再为每个组进行单独的内存分配。
- 连续的本地累加器状态:类型专用的累加器使用 Rust Vec<T> 的某种本地类型,将所有组的值存储在一个连续的内存分配中。
-
矢量化状态更新:内部聚合更新循环,经过类型专门化并使用本地
Vec,被 Rust 编译器(感谢 LLVM!)很好地矢量化了。
备注
一些矢量化分组实现将累加器状态按行直接存储在哈希表中,这通常能有效利用现代 CPU 缓存。以列式方式管理累加器状态可能会牺牲一些缓存局部性,但它确保了哈希表的大小保持较小,即使存在大量组和聚合,也使编译器更容易矢量化累加器更新。
根据重新计算哈希值的成本,DataFusion 28.0.0 可能会或可能不会在表中存储哈希值。这优化了计算哈希值(例如对于字符串来说很昂贵)与将其存储在哈希表中的成本之间的权衡。
将状态更新推送到 GroupsAccumulators 导致的一个微妙之处是,每个累加器都必须处理有/无过滤和有/无输入中空值的类似变化。DataFusion 28.0.0 使用模板化的 NullState,它封装了累加器中这些常见的模式。
代码结构深受 DataFusion 使用 Rust(一种专注于速度和安全性的新(ish)系统编程语言)实现这一事实的影响。Rust 极力不鼓励 C/C++ 哈希分组实现中使用的许多传统指针类型转换“技巧”。DataFusion 聚合代码几乎完全是 安全的,仅在必要时才偏离到 unsafe。(Rust 是一个很好的选择,因为它使 DataFusion 快速、易于嵌入,并防止了许多通常与多线程 C/C++ 代码相关的崩溃和安全问题)。
ClickBench 结果
使用 DataFusion 27.0.0、DataFusion 28.0.0 和 DuckDB 0.8.1 对单个 Parquet 文件运行 ClickBench 查询的完整结果如下。这些数字是在具有 8 核和 32 GB RAM 的 GCP e2-standard-8 机器上运行的,使用了此处的脚本。
随着行业向由组件组装的数据系统发展,它们使用 Apache Arrow 和 Parquet 等开放标准交换数据变得越来越重要,而不是自定义存储和内存格式。因此,此基准测试使用单个输入 Parquet 文件,该文件代表了许多 DataFusion 用户,并与当前分析趋势一致,即避免在查询之前将数据加载/转换为自定义存储格式的昂贵操作。
DataFusion 现在查询 Parquet 数据的速度已接近 DuckDB。虽然我们不打算与一个团队进行基准测试对决,这个团队实际上写了 Fair Benchmarking Considered Difficult,但希望每个人都能同意 DataFusion 28.0.0 是一个显著的改进。
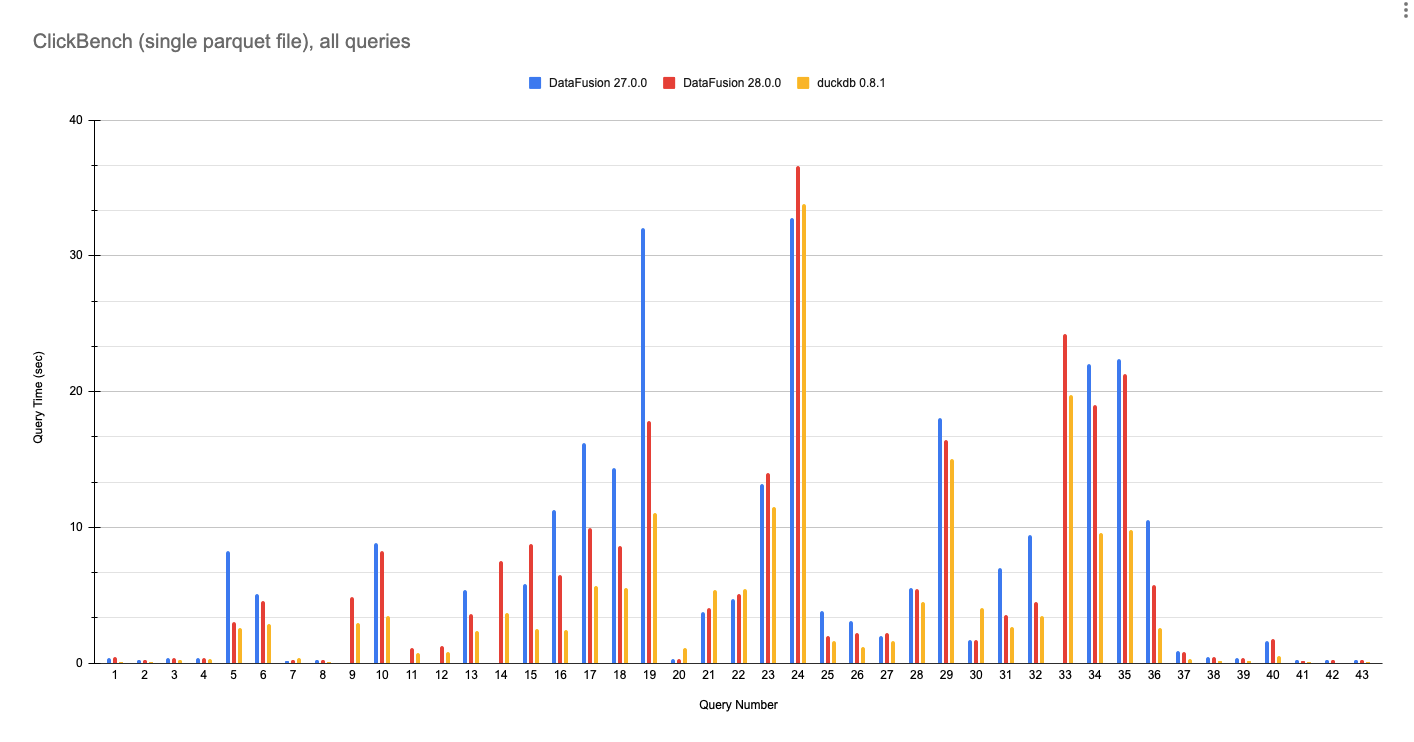
图 6:DataFusion 27.0.0、DataFusion 28.0.0 和 DuckDB 0.8.1 在单个 hits.parquet 文件上执行所有 43 个 ClickBench 查询的性能。值越低越好。
备注
DataFusion 27.0.0 由于规划器错误(Q9、Q11、Q12、14)或内存不足(Q33)而无法运行多个查询。DataFusion 28.0.0 解决了这些问题。
DataFusion 在查询 21 和 22 上比 DuckDB 更快,这可能是由于字符串模式匹配的优化实现。
结论:性能至关重要
将聚合性能提高两倍以上,使使用 DataFusion 构建产品和项目的开发人员可以将更多时间花在增值的特定领域功能上。我们相信使用 DataFusion 构建系统比从头开始构建类似的东西要快得多。DataFusion 提高了生产力,因为它消除了重新构建众所周知但实现成本高昂的分析数据库技术的需要。虽然我们对 DataFusion 28.0.0 的改进感到满意,但我们绝未止步,正在追求 (更多)聚合性能。性能的未来一片光明。
致谢
DataFusion 是一个社区项目,这项工作离不开社区中许多人的贡献。特别感谢 sunchao、yjshen、yahoNanJing、mingmwang、ozankabak、mustafasrepo 以及所有在此工作期间提供想法、评审和鼓励的人。
关于 DataFusion
Apache Arrow DataFusion 是一个用 Rust 编写的可扩展查询引擎和数据库工具包,它使用 Apache Arrow 作为其内存格式。DataFusion 与 Apache Calcite、Facebook 的 Velox 以及类似技术一起,是下一代“解构数据库”架构的一部分,其中新系统建立在快速、模块化组件的基础上,而不是作为单一紧密集成的系统。
备注
-
SELECT COUNT(*) FROM 'hits.parquet';↩ -
SELECT COUNT(DISTINCT "UserID") as num_users FROM 'hits.parquet';↩ -
SELECT COUNT(DISTINCT "SearchPhrase") as num_phrases FROM 'hits.parquet';↩ -
SELECT COUNT(*) FROM (SELECT DISTINCT "UserID", "SearchPhrase" FROM 'hits.parquet')↩ -
hits_0.parquet,来自分区 ClickBench 数据集的文件之一,它有
100,000行,大小为 117 MB。整个数据集在一个 14 GB 的 Parquet 文件中包含100,000,000行。该脚本在 40 分钟后未能在整个数据集上完成,峰值使用了 212 GB RAM。 ↩